パソコンで文字入力を練習していると、
「半角」「全角」
という言葉が、よく出てきますね。
当たり前みたいに使われている言葉ですが、初めてパソコンを習う方にとっては、何のことやらさっぱり分からないですよね・・・・
今日は、この「半角」「全角」って一体何でしょう?? というお話を、改めてきちんと解説してみたいと思います。
まずは簡単に、「半角」「全角」って、こういう感じです
まずは簡単に、「半角文字」「全角文字」のサンプルをお見せします。

こんな感じなんですが、文字の大きさの枠をつけると、こんなふうになります。
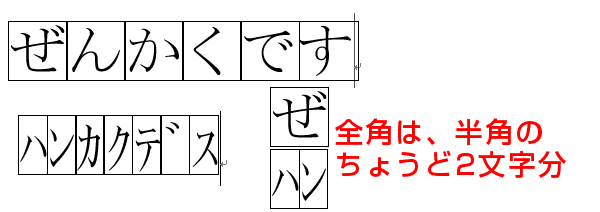
全角文字は、半角文字のちょうど2文字分の大きさです。
※これは、「等幅フォント」=各文字の幅が全部同じである書体の場合です。印刷用のフォントなどでは、等幅でない、文字ごとに幅が違うものがあり、その場合はちょうど2文字分にはなっていません。
ご覧になって分かる通り、全角文字の場合は「せ」に「゛」がくっついて一文字になっていますが、半角の場合は「テ」と「゙」が別々に2文字になっていますね。実は、半角の場合、総文字数を減らす目的で、文字と濁点を分けてあります。(このあとの解説をごらんください)
どうして、半角と全角なんて、2種類も文字があるの?
ではどうして、文字が二種類もあるなんていう、ややこしいことになっているのか、というお話をします。話は、コンピュータが生まれたころまでさかのぼります。
昔のコンピュータには、半角文字しかなかった!!
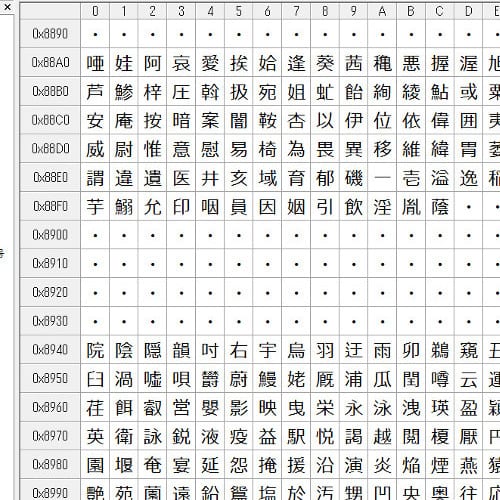
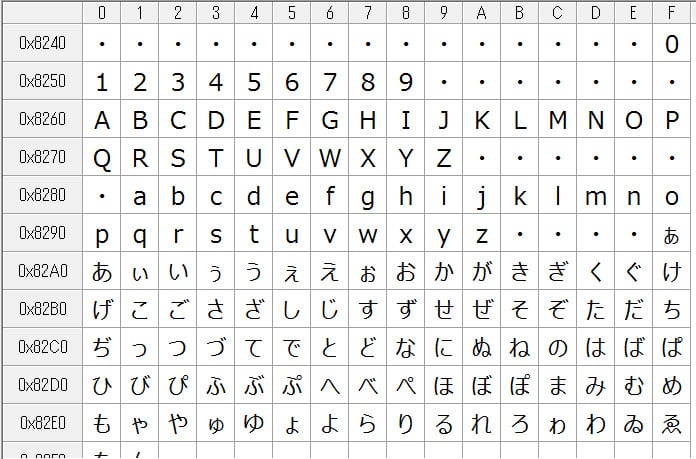
実は、いちばん初期のコンピュータには、半角文字しかありませんでした。最初はアルファベット(英語)しかなかったのですが、1969年になって、カタカナが追加されたころの文字一覧がこちらです。

初期のパソコンの文字コード表。256文字しかありません。最初の方の「SH」とか「SX」は、特殊な機能をもった文字です。
この表は、すべて「半角文字」しかありません。
ちょっとややこしいお話をしますが、原理がわかると理解も深まりますので、どうかお付き合いお願いします・・・(;^_^A
半角文字は、2進数8ケタ=「8ビット」で表現できる
この表の「ア」のところを見てみてください。

このように読み取りまして、「ア」の文字コードは「B1」です。
「B1」というのは、16進数です。いつも私たちが使う数字は、「10になると上のケタに繰り上がる」ので「10進数」といいます。10進数は、「0123456789」の10個の数字で表しますが、16進数は、数字が「0123456789ABCDEF」と16個あり、16になると上のケタに繰り上がって「10」と表記します。
よく「コンピュータは0と1だけで動いている」と言われますが、0と1だけで数を表すことを「2進数」といいます。数字が「0 1」の2つしかないため、「2」になると上のケタにくりあがります。
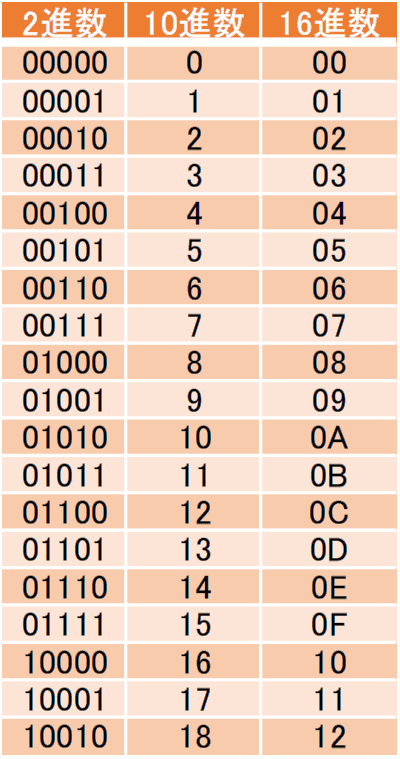
2進数、10進数、16進数の例です。
これでいくと、16進数「B1」=10進数「177」となります。
「ア」を表す「B1」を、2進数になおすと「1011 0001」です。8ケタありますね。2進数8ケタのことを「8ビット」といいます。
「64bit(ビット)」とか、「32bit(ビット)」という言葉を、パソコンのことで耳にしたことがないでしょうか? あの「ビット」です。
いまのパソコンはほとんど、いっぺんに64ビットの情報を読み取ります。すごい高性能になりました。
最初のころのパソコンは、いっぺんに読める情報量は、たったの8ビットでした。
だから、文字も8ビットで定められました。文字数は、2×2×2×2×2×2×2×2=256文字しか表現できませんでした。
これが、現在いうところの「半角文字」なんです。
漢字を表現するため、文字コードは16ビットに拡張され、「全角文字」ができました
1980年代中期になりますと、日本でパソコンが普及してきます。すると、「漢字が使いたい!」というニーズが強くなってきました。
ところが、漢字はものすごく文字数が多くて、8ビットの文字コードではぜんぜん足りません。
そこで、16ビットの文字コードを使って漢字を表現する方法が考案されました。
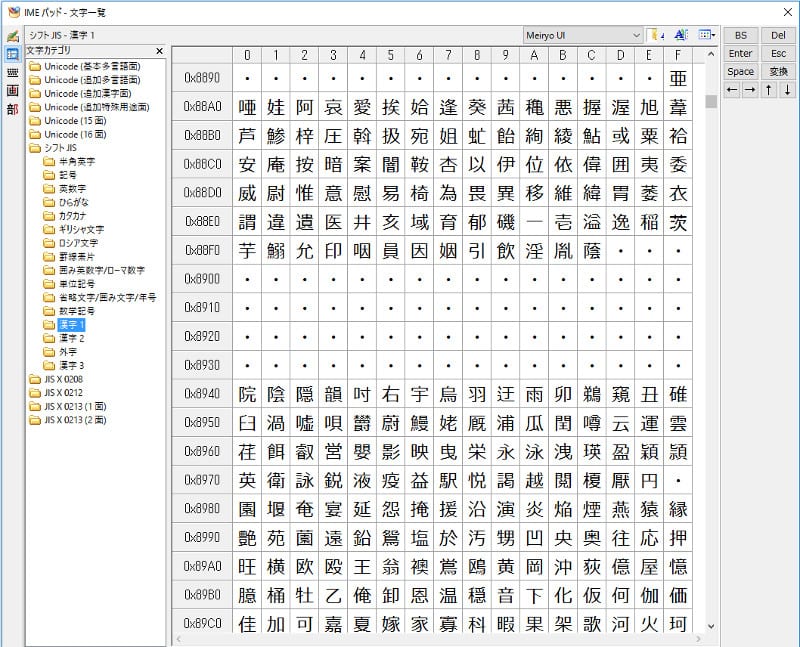
Windowsの「IMEパッド」で見ることができる、漢字の文字コード
この表は、現在お使いのパソコンで、右下の「あ」とか「A」を右クリック→「IMEパッド」を選択すると、見ることができます。
たとえば「亜」の文字コードは16進数で「889F」です。2進数になおすと「1000 1000 1001 1111」となり、16ケタ(16ビット)あるのが分かります。取り扱える文字数は、2×2×2×2×2×2×2×2×2×2×2×2×2×2×2×2=65536文字まで増えました! 漢字も十分入りますね!
これが、全角文字です。
そしてこのときはじめて、もともとあったコンピュータの文字は、「全角」の16ビットの半分、8ビットで表現できることから、「半角文字」と呼ばれるようになりました。
半角の「A」と、全角の「A」って、どうして同じじゃないの??という疑問。
コンピュータの中では、全角文字と半角文字は厳格に区別されています。
区別しなくて大丈夫な場面もありますが、それは内部で自動的に変換されているからで、「半角」と「全角」の文字は、たとえ同じ「A」であっても、あくまで別物です。
エクセルを例にとると、セル参照で半角で「A3」と打つべきところを、うっかり全角で「A3」と打ってしまうと、正しい計算結果が出ません。先日、MOSの資格を取ろうとしている生徒さんのレッスンで、「どうしても正解にならない」というご相談があり、確認したところ、原因はこれでした。
どうしてこんなややこしいことになっているんだろう?? と疑問に感じる方もいらっしゃると思います。
実は、もともと8ビットでも存在した文字についても、日本語の文章に違和感なく入れられるよう、16ビットの新しい字形が定められました。
2種類の「A」をならべると、こんな感じです。
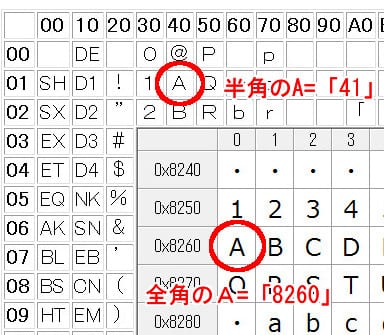
半角と全角の「A」の比較
このように、人間の見た目には両方とも「A」なんですが、コンピュータにとっては全く別物、「41」と「8260」であることが分かります。
そういうわけで、半角と全角の文字を打ち間違えると、コンピュータにとっては全然違う意味になってしまうんです。
パソコンの進歩で、世界中の文字が表現できるようになりました
日本語では、文字コードはせいぜい16ビットでおさまりますが、世界中には本当にいろんな文字があります。そんな文字を全部パソコンで表示しようとしたら、16ビット=65536文字では全然足りません。
そこで現在は、Unicode(ユニコード)という仕組みが世界共通規格として作られ、世界中の文字がパソコンに表示できるようになっています。
例えばこれをご覧ください。
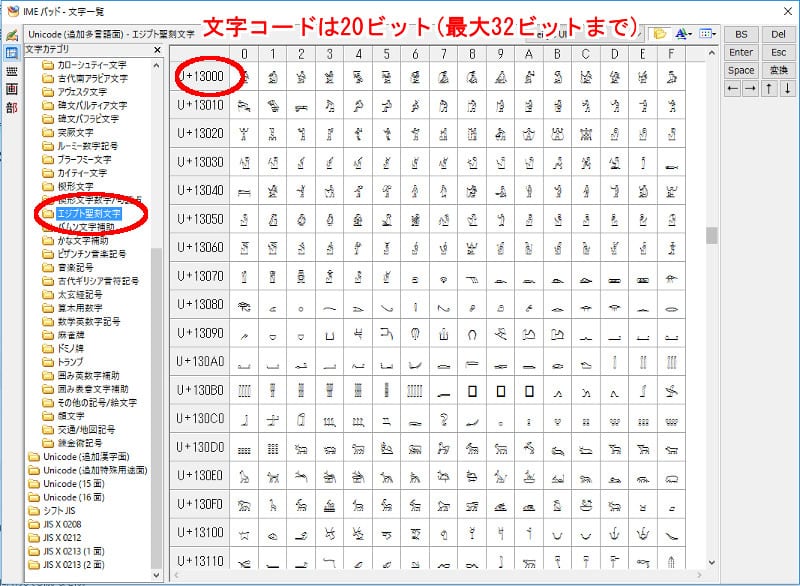
古代エジプト文字に割り振られた文字コード
こんな文字コードまで定められたおかげで、パソコンで古代文字まで入力できちゃうのです。(※エジプト古代文字が描かれていないフォントでは表示されませんので、このブログでも表示はできません)
これらの文字は、20ビット使用しますので、半角文字の2.5文字分です。もはや「全角文字」と呼ぶのも通じにくいので、多くの場合、単に「ユニコード文字」と呼びます。
このユニコードは、最大で32ビットまで対応し、符号に使う1ビットを除くと、対応可能な文字数はなんと21億文字に達します!!
すごいですね!!!!
とまあ、こんな驚きを感じながら、全角/半角文字を、正しく使い分けてくださいね!!
コメント