Excel / PowerBIでは、Power Queryを使用してデータを取得します。
累積を計算する方法はいろいろ載っているのですが、累積されたものから個別データに戻す方法は、あまり見ないのでまとめてみました。
例として、厚労省オープンデータの「新型コロナ死者数(累積)」を使用します。

クエリ1:ソースを単純に読み込んだもの
この手順では、ソースデータを2回読み込みます。
そのまま組むと、データソースへのアクセス数が不必要に増えてしまう可能性があるので、まずソースを生のまま読み込んだクエリをひとつ作ります。
これ自体をワークシート上に展開する必要はないので、「接続の作成のみ」
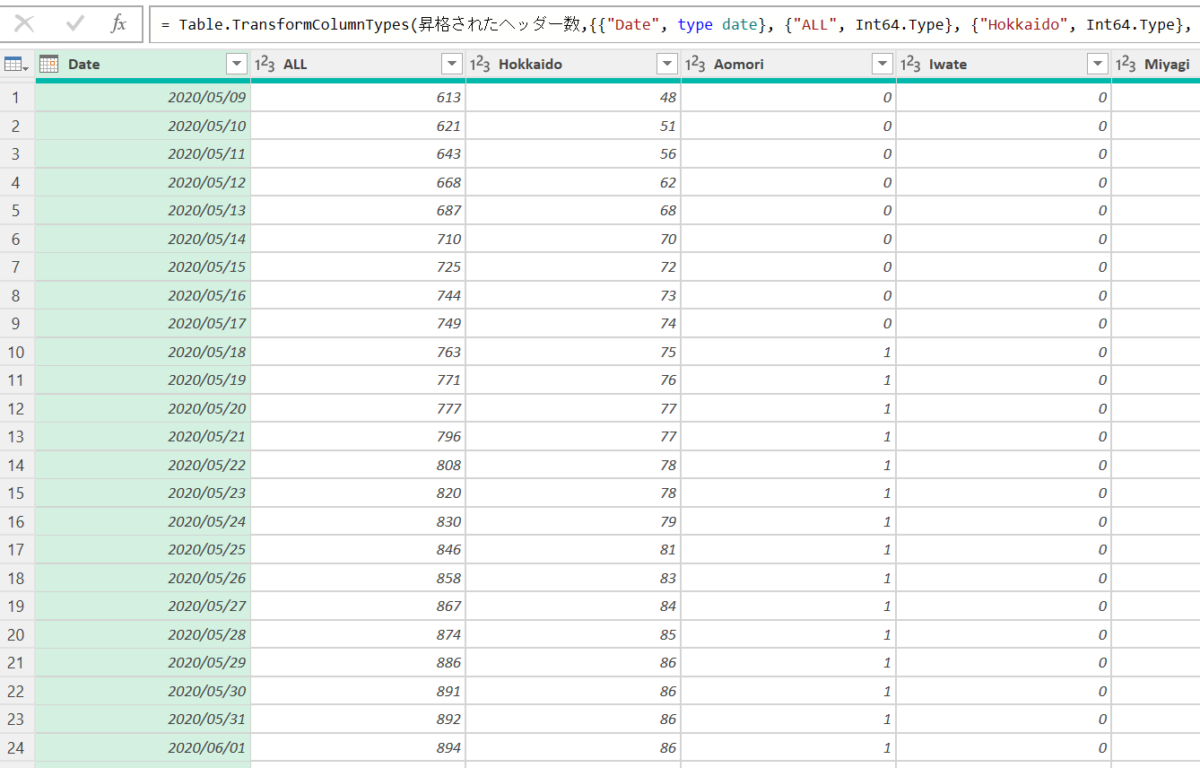
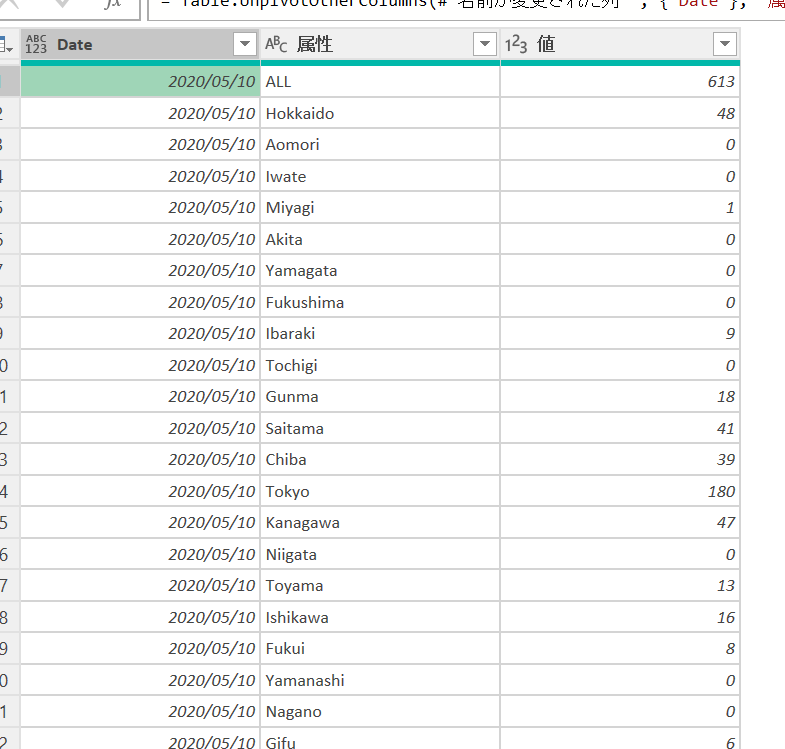
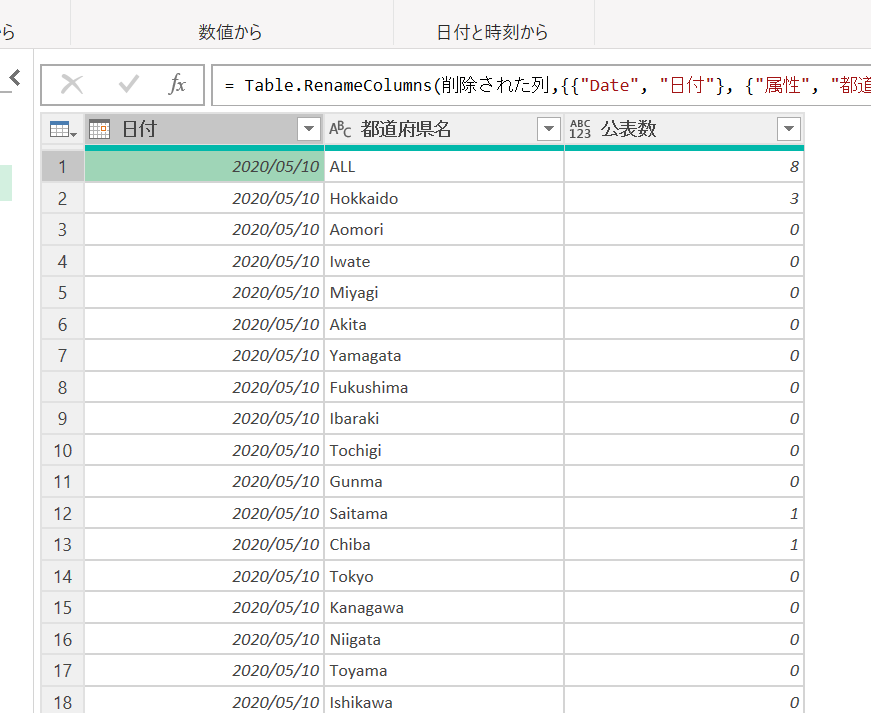
プレビューで見ると、このようなデータです。
例えば、5月10日に各都道府県で発表された死者数は
5月10日の発表数 - 5月9日の発表数 で得られます。
この計算を、Power Query上で実現しようというわけです。
全都道府県分のカスタム列を作るのは、さすがに非合理的
インデックス列を追加するなどして、引き算をカスタム列として追加すればいいように見えますが、それは列数が少ない場合です。
47都道府県+全国ですから、48列あります。48個カスタム列をじゅんじゅんに追加するのは、さすがに参ってしまうわけです。
そこで次のような方法をとりました。
クエリ2:クエリ1を参照し、日付を一日ずらす
そこでどうしたかというと、もう一個サブクエリを使いました。
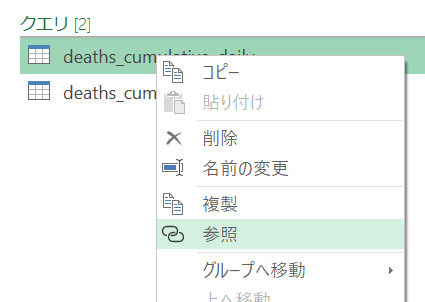
まずは、いま作った、データソースのためのクエリを右クリック→「参照」します。
こうすることで、データソースを再び読み込むことなく、同じデータを参照できるようになります。
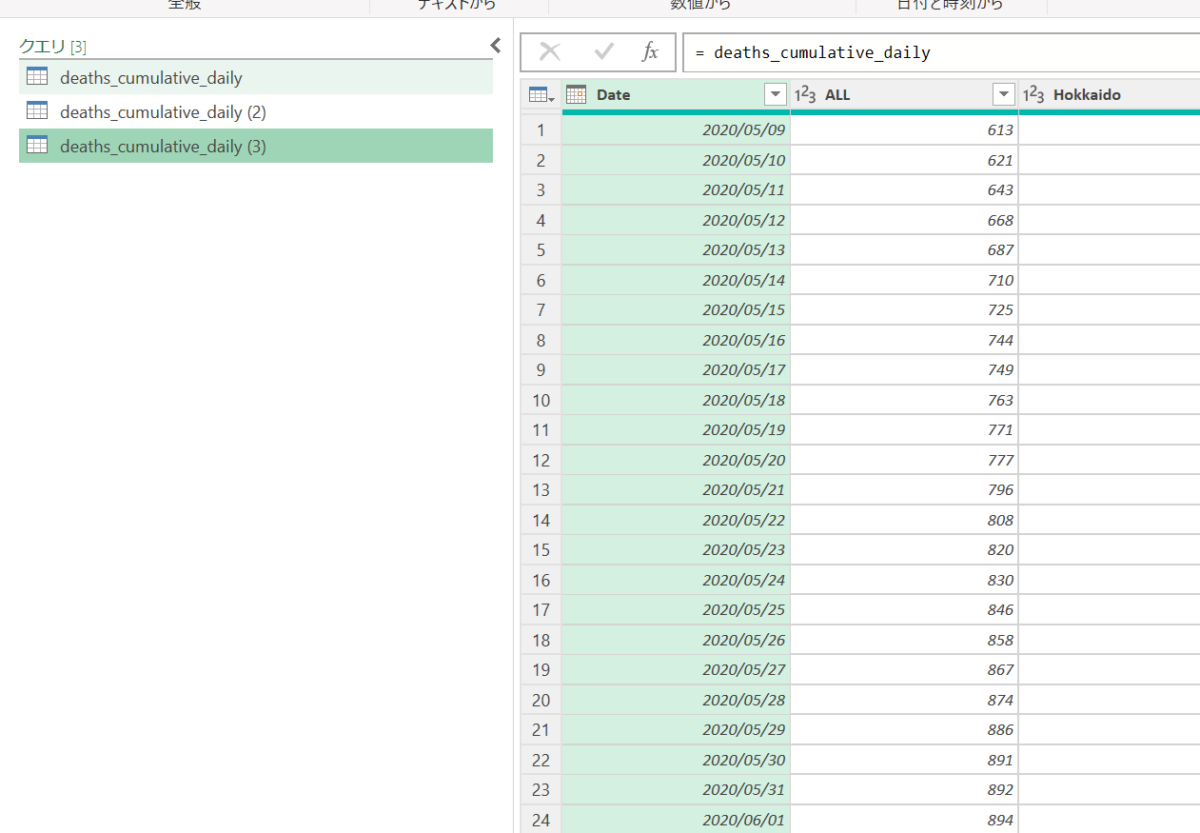
日付を一日ずらしたカスタム列を作る
ここで、「日付に1日を足したもの」をカスタム列として作成します。
![=[Date]+#duration(1,0,0,0)](https://curio-shiki.com/blog/wp-content/uploads/2022/11/image-8.png)
日付型に足し算する場合は、エクセルのように単純に1は足せません。 #duration(日,時,分,秒)を使います。
そして、できたカスタム列を「先頭に移動」します。
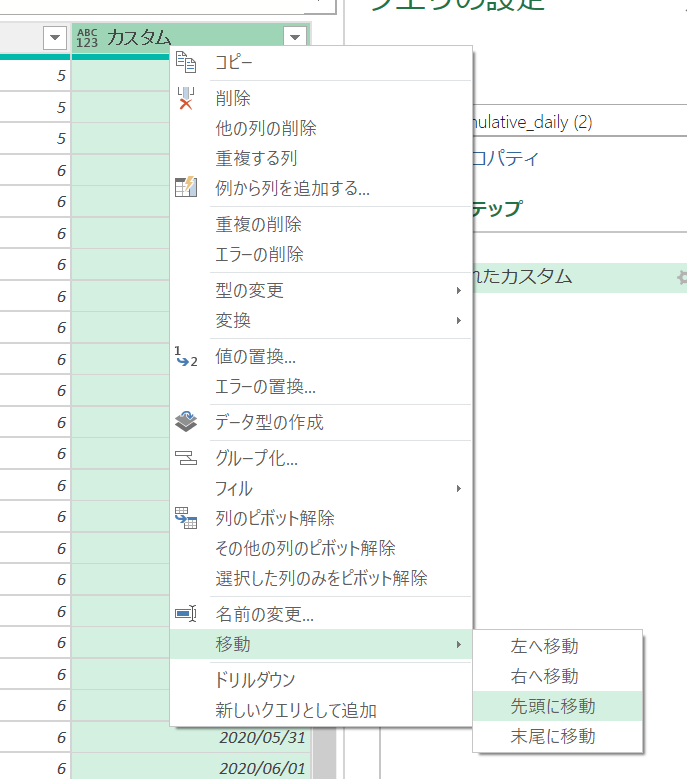
これで、「【カスタム】の日付のデータから引き算すべきデータ」ができます。
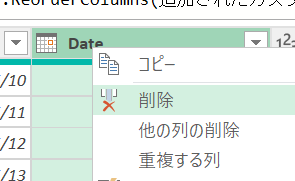
Date列を削除し、「カスタム」列を新たに「Date」という名前に変更しておきます。これは、次の手順の準備です。
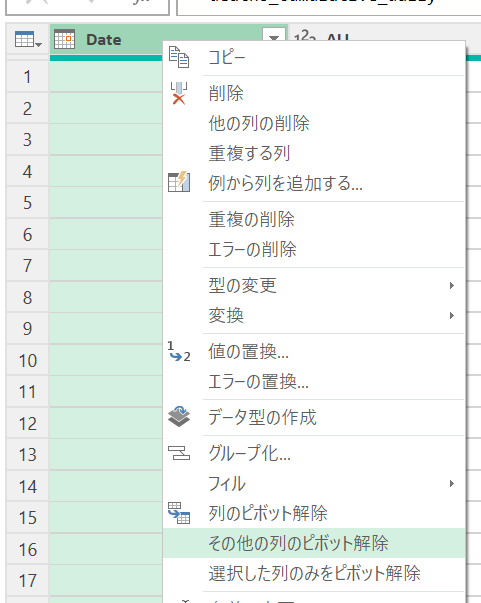
「その他の列のピボット解除」
続いて、Date列を除くすべての列を「ピボット解除」して、列数を削減します。
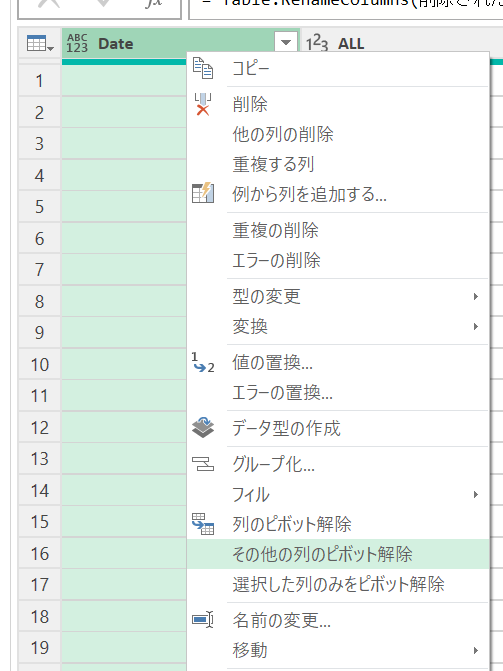
データ列が一列だけになり、計算しやすくなりました。
ここまでが、サブクエリの準備です。これを使って、メインクエリを組みます。
クエリ3:結果を出すためのメインクエリ
メインクエリも、同じソースクエリを「参照」して作成します。
このまま「その他の列をピボット解除」して、計算できる状態にする
こちらは、日付をずらさずに、このままDate列を選択して「その他の列をピボット解除」します。
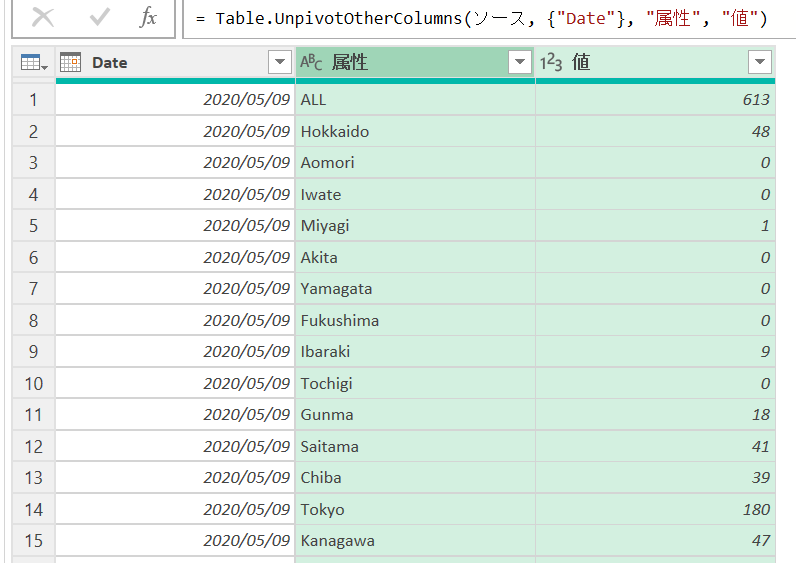
さきほどとよく似たデータですが、こちらは厚労省が発表したままの日付になっています。
サブクエリと「マージ」
ここで、[Date]と[属性]をキーにして、さきほど作ったサブクエリと【マージ】します。
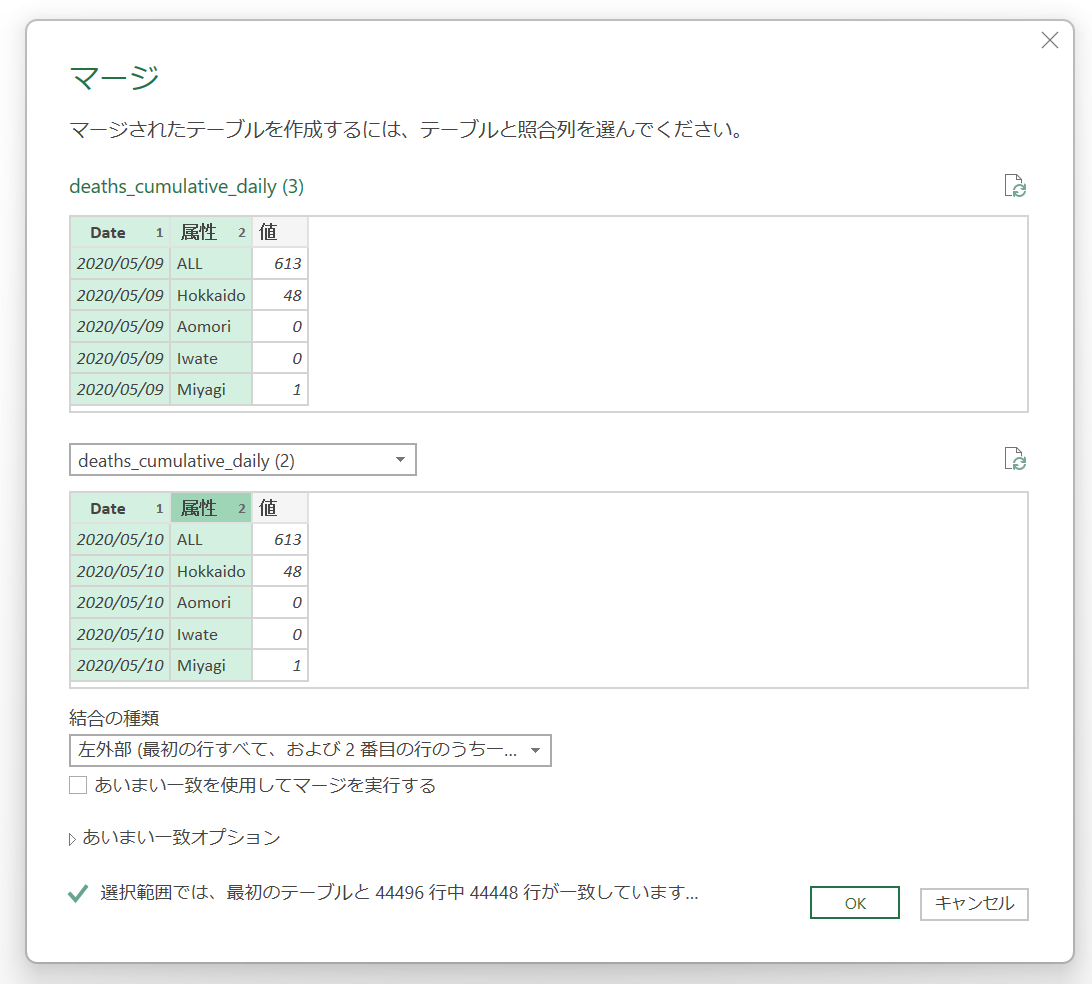
一致している行数が少ないと思いますが、これは一日ずらしたために、ちょうど一日分の不一致が出ているわけですね。
実行するとこのようになります。
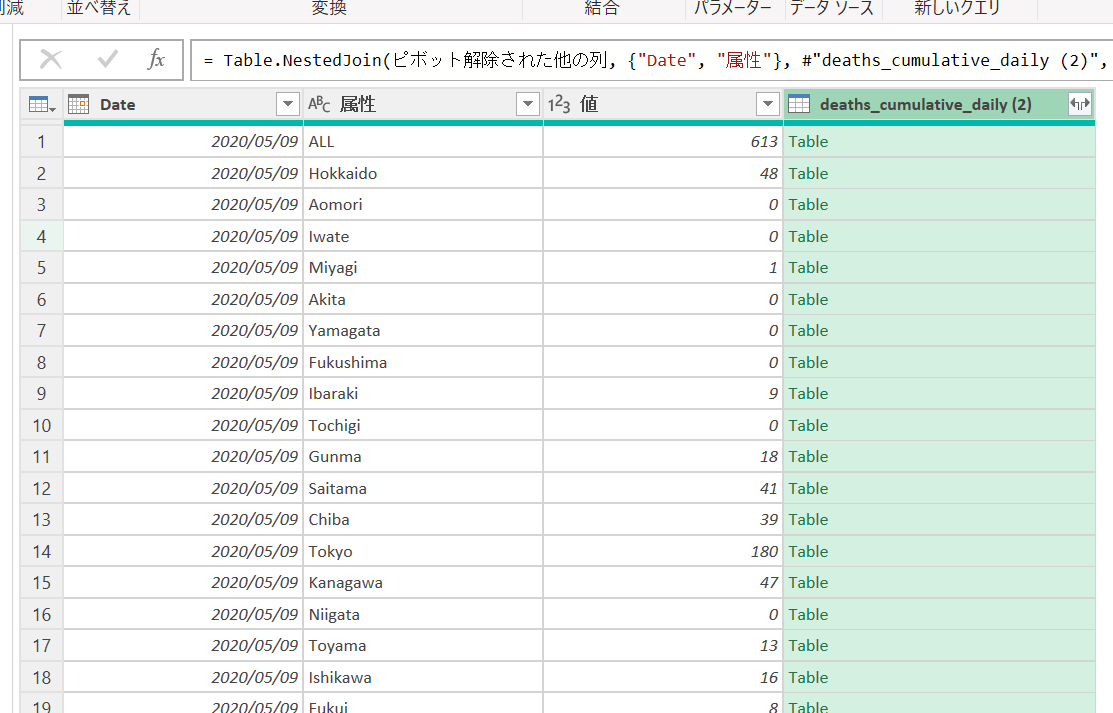
テーブルを展開してみます。
必要なのは[値]列だけなので、チェックは[値]だけにつけます。元のテーブルの[値]とだぶるので、元の列名をプレフィックスとして使用して回避します。
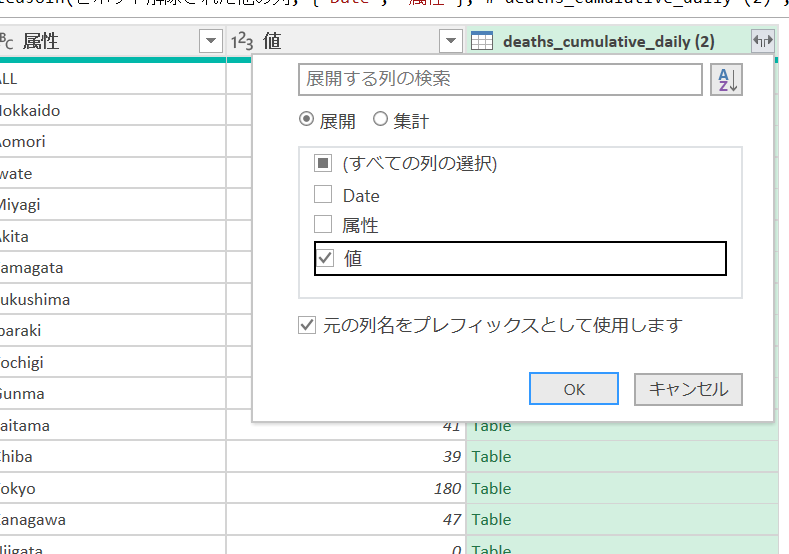
実行するとこのようになります。
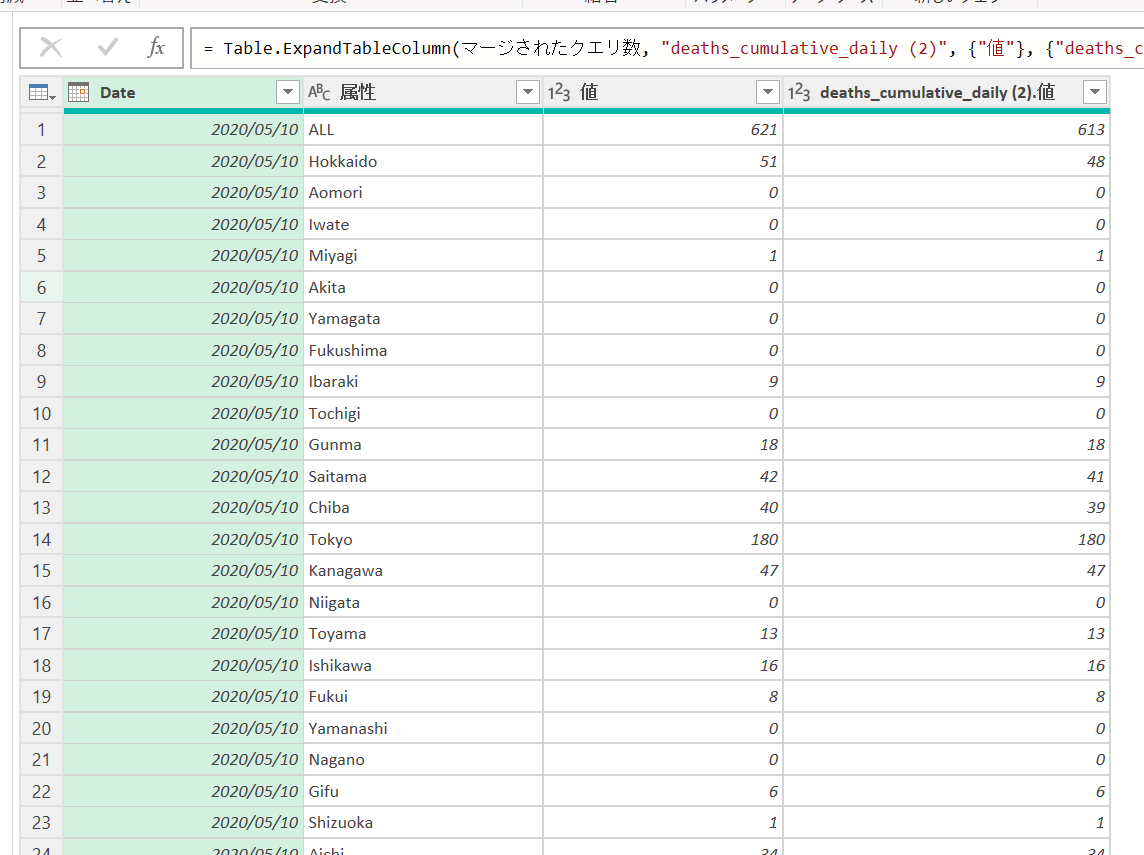
元のデータには、2020/5/9のデータがありましたが、テーブルを展開すると、5/9のデータから引き算するべきデータは存在しなかったため、削除されて、5/10からのデータに変わりました。
もともと、2つのクエリの並び順はたぶん一致しているんですが、日付と属性(都道府県名)でマージしているため、仮に並び順がちがっていても、正確に、都道府県別の当日・前日の累積数が一レコードに並ぶことになります。
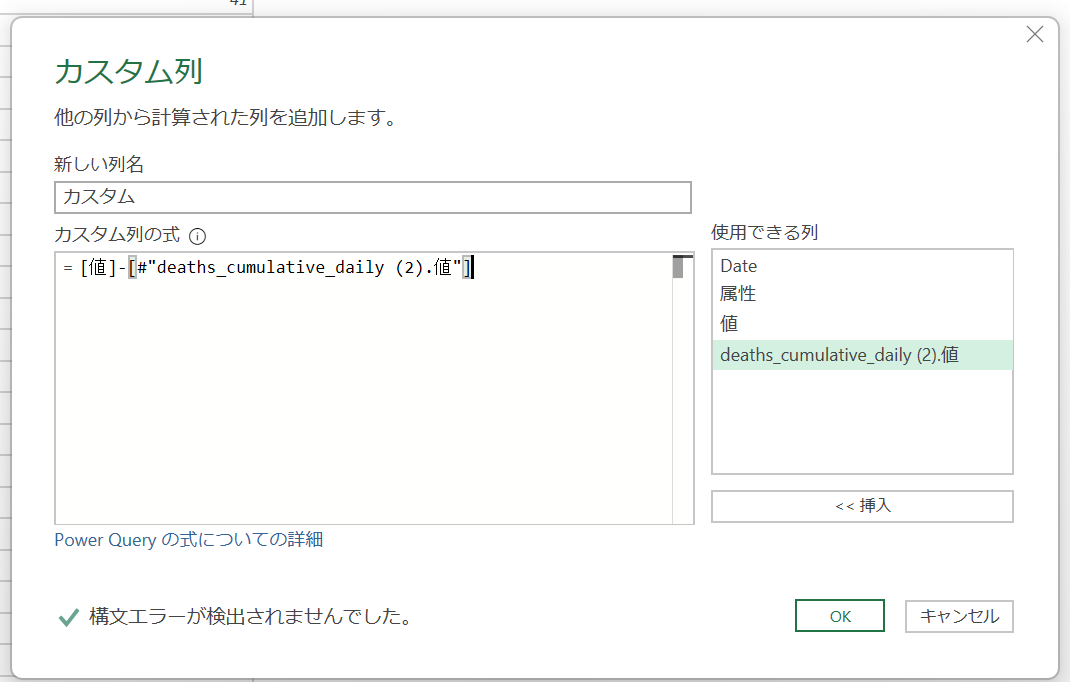
ふたつのデータを引き算して、カスタム列に日毎発表数を得る
あとは簡単ですね。両方の数字を引き算するカスタム列を作成します。
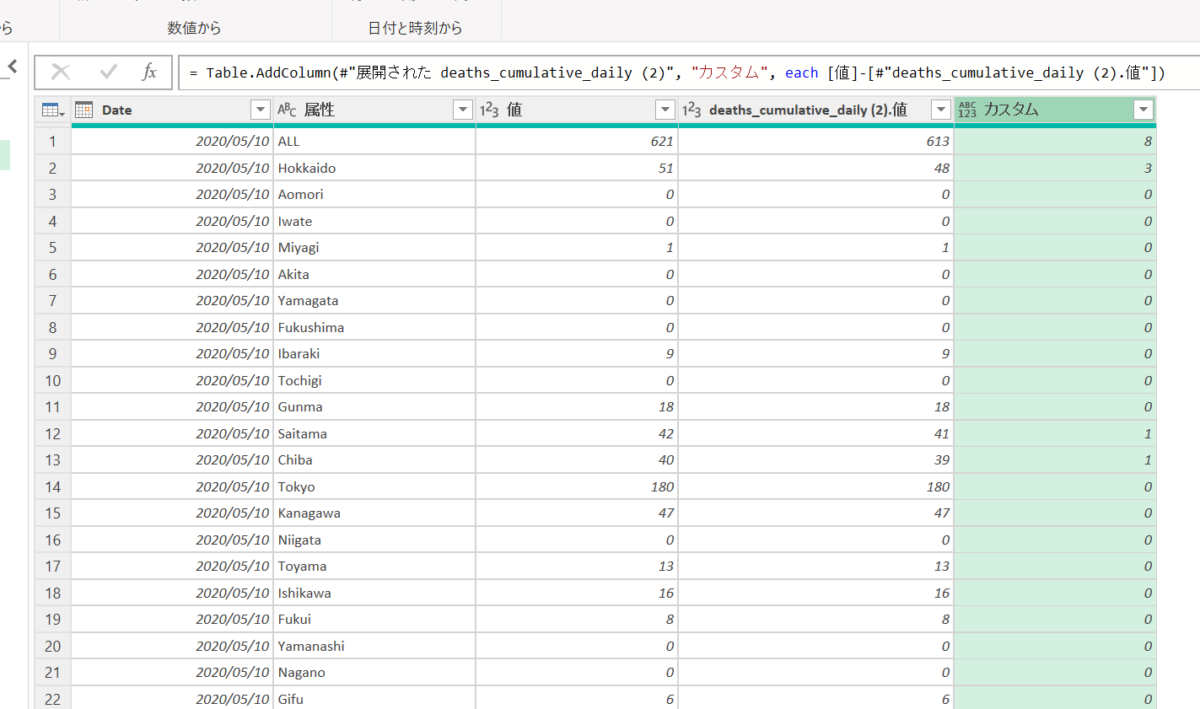
欲しかった数字がでましたので、計算に使った列はもう必要ありません。削除して、列名をととのえます。
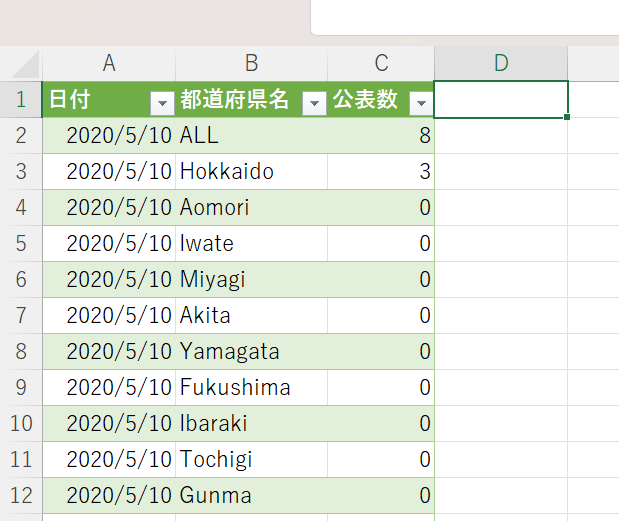
完成したデータ
以上の手順で、都道府県別の累積データから、日毎の発表数データを作ることができました。
ワークシートに読み込んでみます。「閉じて読み込む」
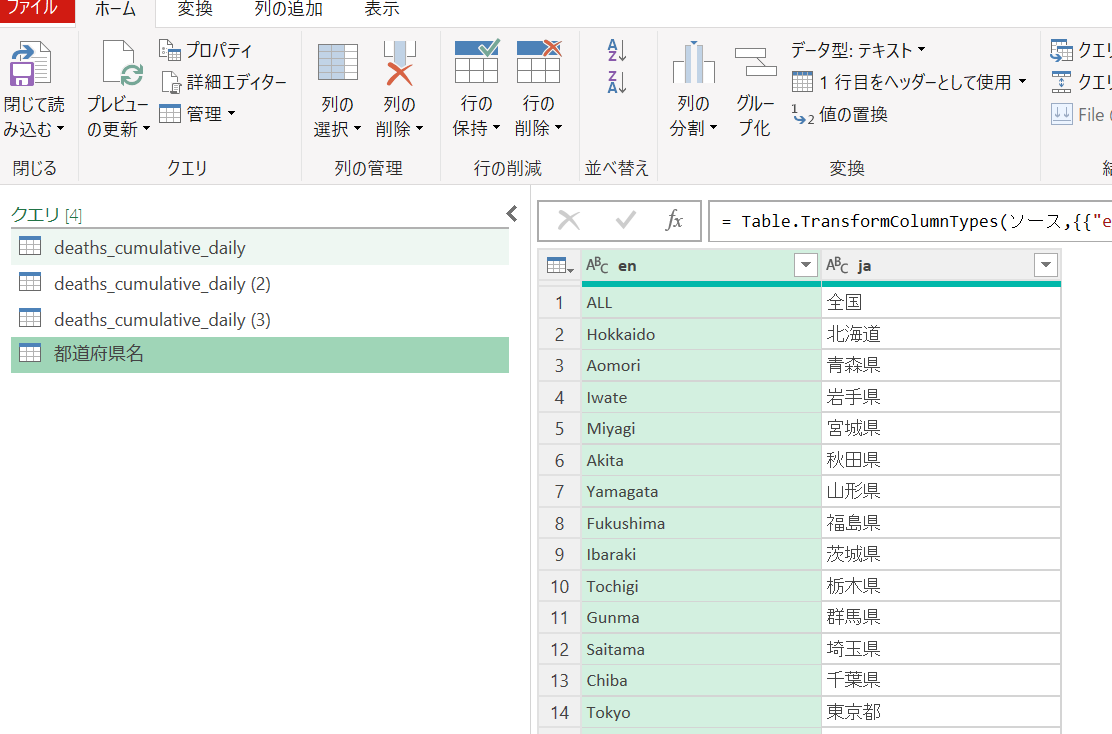
追記:都道府県名を日本語になおす
追記として、厚労省データでは都道府県名が英語表記になっているので、これを日本語になおしてみます。
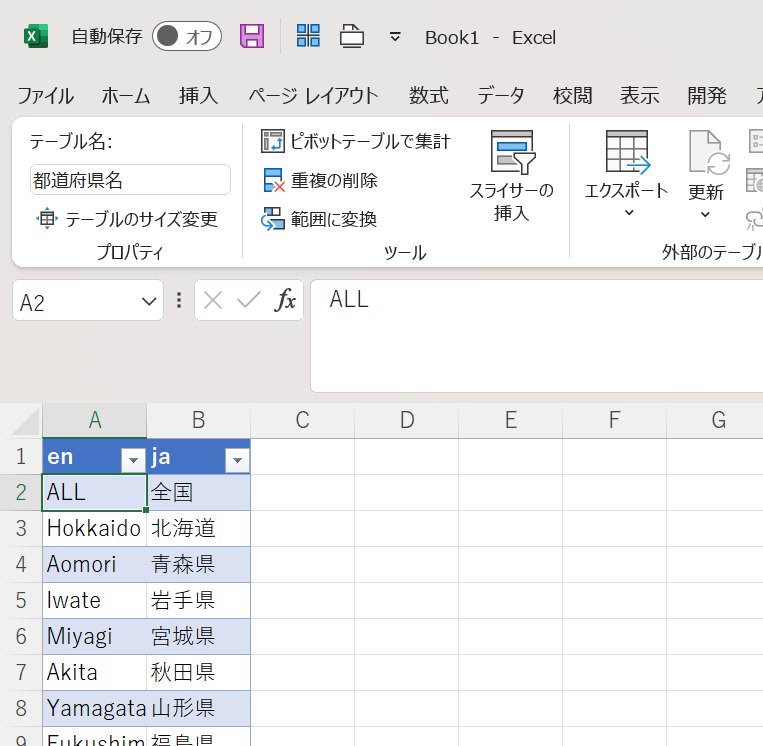
都道府県名の英語→日本語の一覧表をつくり、クエリとして読み込む
まず、面倒ですが都道府県名の英語→日本語の対照表を作ります。
Google検索すると、そのような表を公開してくれているサイトがいくつかあるので、そこからコピペでいただいてもよいかもしれません。
当店の場合は、しょっちゅう使うので、どこかのブックにはいっているものをコピーしてきました。
表を作ったら、テーブルにしてテーブル名をつけておくと、読み込んだ時この名前のクエリになるので楽です。
できたら、これを「テーブルまたは範囲から」で読み込みます。
これを改めてワークシートに読み込む必要はないので、「読み込み先」を「接続の作成のみ」にしておきます。
一覧表を使ってテーブルの列を一括置換する
この一覧表を使って、テーブルの列を一括置換します。
こちらのサイトを参考にさせていただいています。

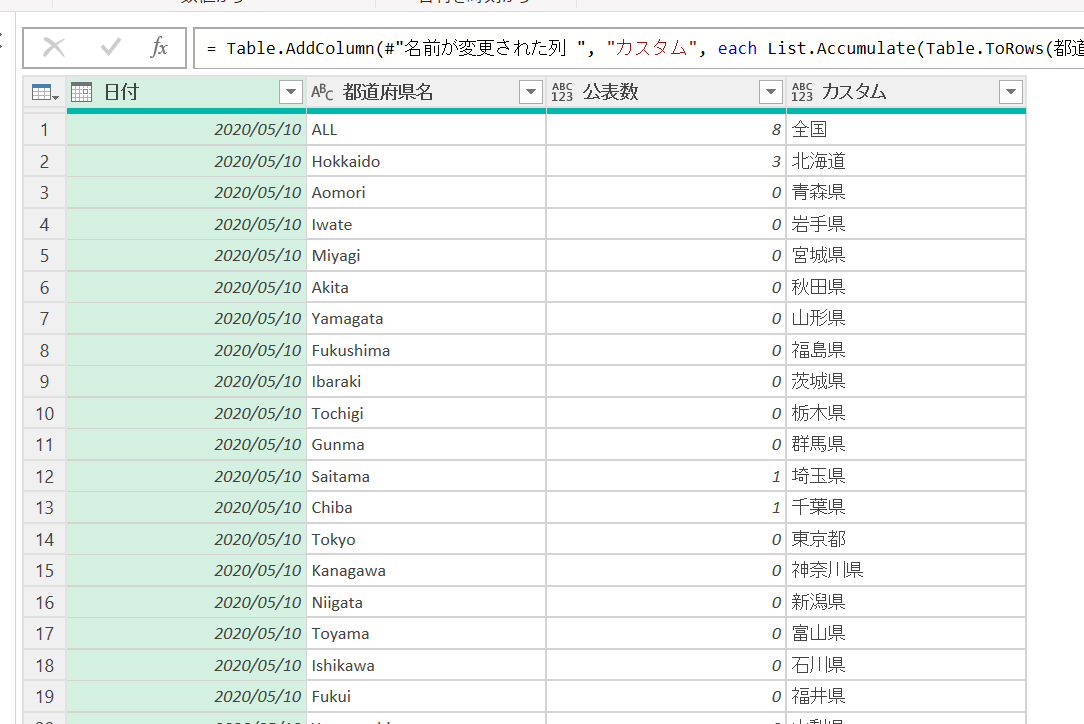
さきほど完成したメインクエリに、次のようなカスタム列を追加します。
![=List.Accumulate(Table.ToRows(都道府県名),[都道府県名],(x,y)=>Text.Replace(x,y{0},y{1}))](https://curio-shiki.com/blog/wp-content/uploads/2022/11/image-32.png)
=List.Accumulate(Table.ToRows(都道府県名),[都道府県名],(x,y)=>Text.Replace(x,y{0},y{1}))すると、このように置換されたものがカスタム列として生成されます。
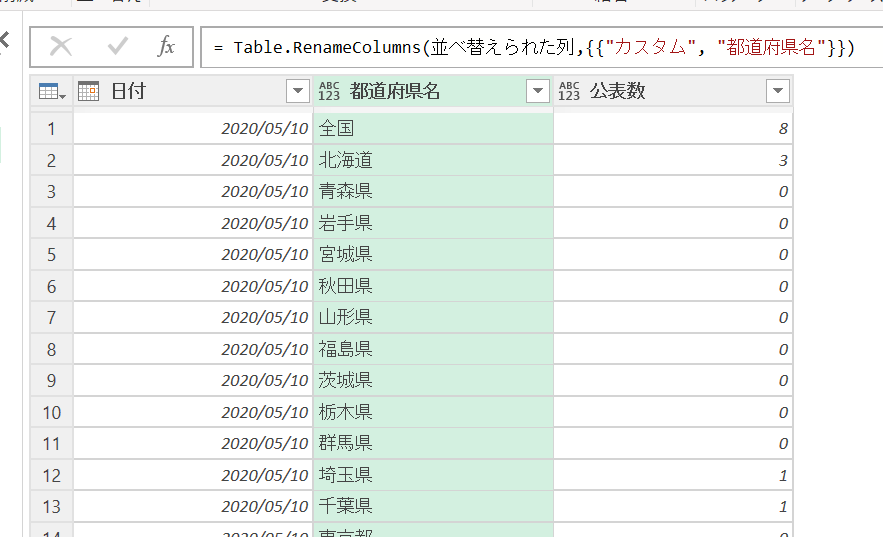
あとは、もとの[都道府県]列を削除してととのえれば完成です。
※行数が非常に多い場合は、動作が遅いので要注意
この一括置換はたいへん便利なのですが、行数が数十万行~数百万行のデータに対して行うと、動作が猛烈に遅くなるので注意が必要です。
行数が多い場合のベストプラクティスとして、「ステップを追加し終わるまでは、先頭の少ない行のみを保持して作業し、最後にそのステップを削除する」ことがMicrosoftによって推奨されていますが、

残念ながらこの件については、この方法をとったとしても、最後の読み込み段階で動作が遅くなり、データモデルに読み込ませるために半日を要するようなことが、実際にありました。
ご注意ください。
コメント