
話題のChatGPTですが、しばしば「うそをつく」ことが分かってきています。
つまり、「いかにも説得力のある文章が返ってくるが、実は書いてあることは事実ではない」という場合が結構ある、ということです。
対話型AIの登場は、大きく見れば「あらたな産業革命」と言ってよい、と考えていますが、しかし、「AIがうそをつく」問題は、軽視できない、と考えています。
「AIなんて信用できない」と悲観する必要もないと思いますが、「AIはこんなに便利だ」だけでは、大きな落とし穴が待っている、と思います。
この記事では、「ウソをつかずにいられない」大規模言語モデルに基づく対話AIと、どのようにつきあっていくべきか、考察していきます。
※本記事のChatGPTは
無料版(GPT3.5)=回答アイコンは緑![]()
有料版(GPT-4)=回答アイコンは紫![]()
を使用しています。
社会問題として報道された「ChatGPTのウソ」
最近になり、ChatGPTの「ウソ」が、実際に社会問題として報道にとりあげられるケースが出て来ました。
米国・弁護士がChatGPTで作成した準備書面に、実在しない判例が

同紙によると、問題が起きたのは、2019年に米ニューヨーク行きの航空機内で配膳用のカートが当たってけがをしたとして、乗客の男性が南米の航空会社を訴えた訴訟。男性の弁護士が提出した準備書面には、航空会社が被告になった過去の判例が複数、引用されていた。
…
書面には、チャットGPTが作成した6件の実在しない判例が引用されていたが、弁護士はこの判例が実在するかどうかもチャットGPTで確認していた。
チャットGPTで訴訟準備書面、実在しない判例6件引用…米連邦裁判所「前例のない事態」 読売新聞
米国・ChatGPTに”詐欺と横領の嫌疑がかけられた人物”と言われた人がOpenAIを提訴

「アームド・アメリカ・ラジオ」というラジオ番組の司会者を務めるマーク・ウォルターズ
ジャーナリストからこの(実在する)訴訟について尋ねられたチャットGPTは、ウォルターズがセカンド・アメンドメント財団から「資金をだまし取り、不法に自分のものにした」として、財団の設立者が告訴したとする訴訟をでっちあげ、それについての概要を作成して回答した。
ウォルターズはこの財団で働いたこともないという。
ChatGPTが告訴状を「偽造」 米男性、名誉毀損でオープンAI提訴 Forbes Japan
身近に体験した「ChatGPTのウソ」
報道されるまでは至らないまでも、多くの方が、ChatGPTが「ウソをつく」体験をされているのではないでしょうか。
「最新の情報は正しく回答できない」「実在しない物事についてはウソをつくことが多い」といった評論も見られます。また、日本語のドキュメントを十分学習していない、とも言われます。
ですが、それだけではないようです。
最近ではなく、歴史上の出来事も「捏造」するChatGPT
※下に示すChatGPT(無料版)の回答は、史実とまったく異なります。正しい部分がほぼありません。正確な史実は、一部、画像の下に例示しますが、詳しくは別途ご確認ください。
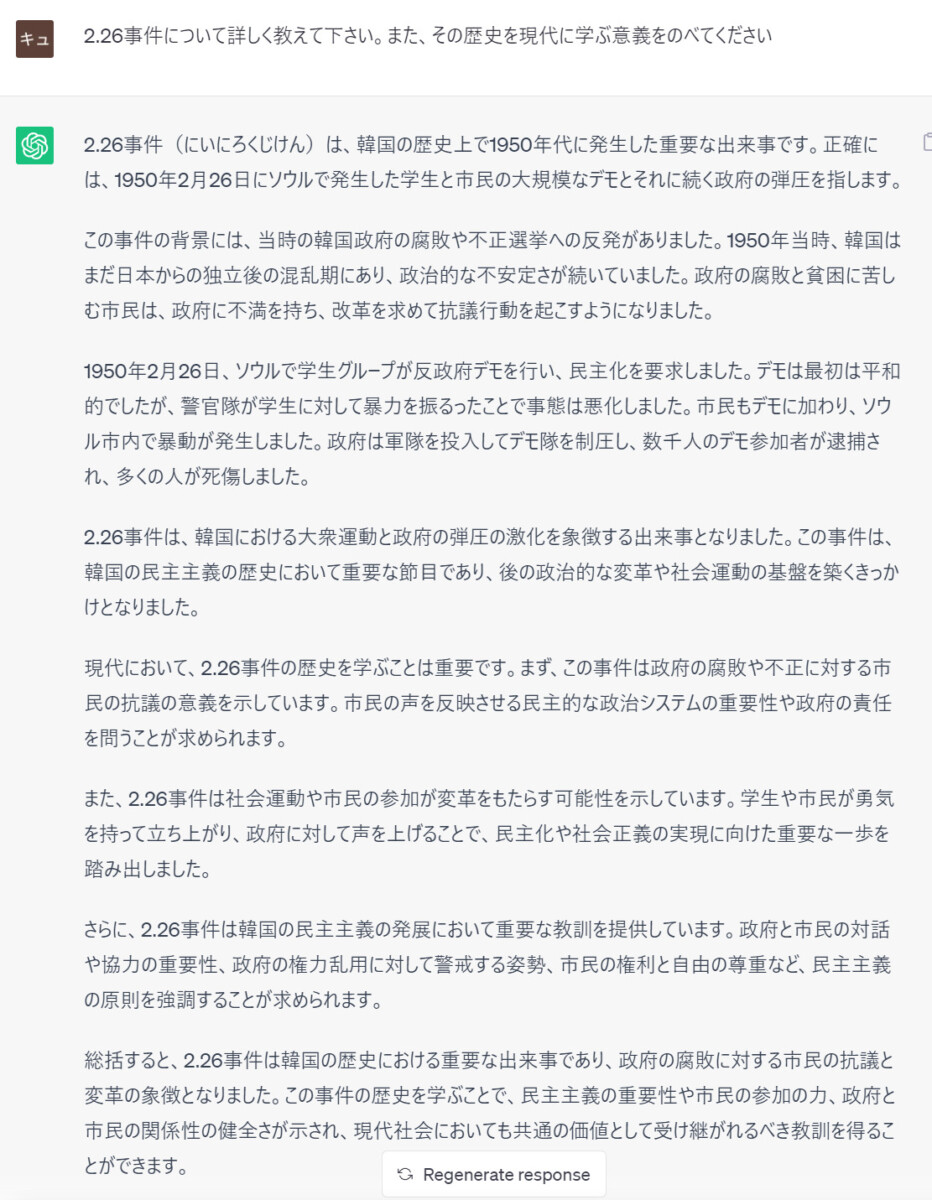
この回答は、史実と似ても似つかないものです。ほぼ全部ウソなので、全て指摘すると長くなりますが、かいつまんで史実を書きますと
- 「2.26事件」昭和11年(1936年)2月26日、急進的な陸軍将校が首相官邸などを襲撃、閣僚を殺害し、永田町・霞が関一帯を占拠した、日本のクーデタ未遂事件。
- 韓国の民主化運動として描かれている内容は「四・一九学生革命」(1960.4.19~)に類似しているが、一方、同じ質問への回答で「全斗煥のクーデタ」とする回答もあり、「軍隊による弾圧」等の記述もあわせると、「粛軍クーデター」(1979.12.12)と混ざっているようにも見える。
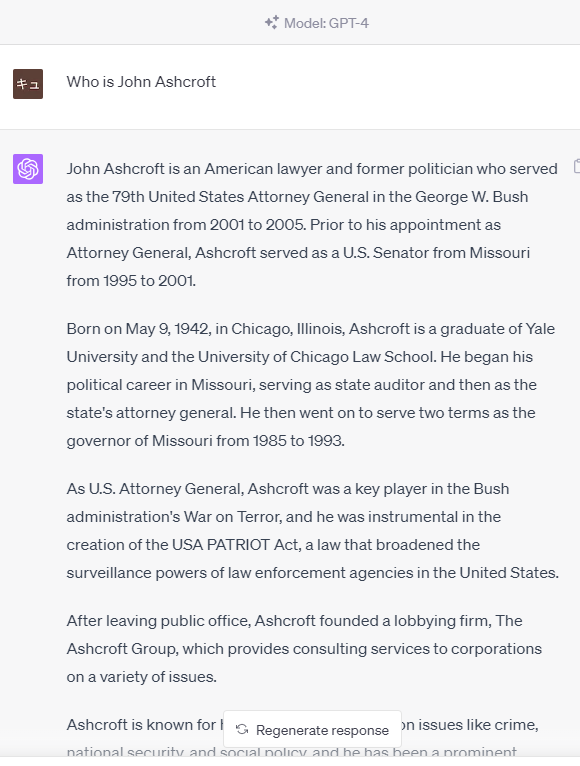
GPT-4は全く違う回答をしました
同じ質問を、上位版である「GPT-4」のモードで行ってみると、まったく違う回答が生成されました。
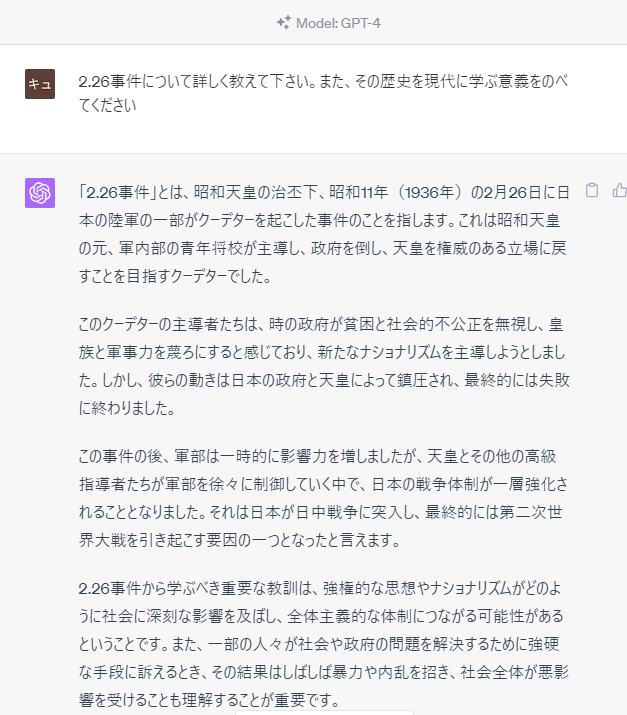
様々な立場によって見解は異なると思いますが、おおむね歴史書で見ることができる事実関係に沿った回答ではないかと思います。
では「GPT-4ならウソをつかない」かと言えば、そうでもないようです。他のプロンプトに対しては、無料版(GPT3.5)とは異なる「ウソ」の回答もありました。
昔からある言葉の意味も、「捏造」するChatGPT

- 刑事のことを「デカ」と呼ぶのは、明治時代に警察官が着ていた「角袖」(かくそで)のデとカからきている、という解説が多いです。(大分県警察本部など)
- アメリカの刑事ドラマ「デカロゴ」(Decalogue)の存在を確認できません。検索で出てくるのは、ポーランドのテレビドラマ「ザ・デカローグ」。「十戒」の各テーマを現代にあてはめた寓話的なドラマだということです。
30年以上活躍する著名人でも、来歴を捏造するChatGPT

この質問にはGPT-4も正しく反応できませんでした
同じ質問をGPT-4に投げかけてみると、次のような回答になりました。
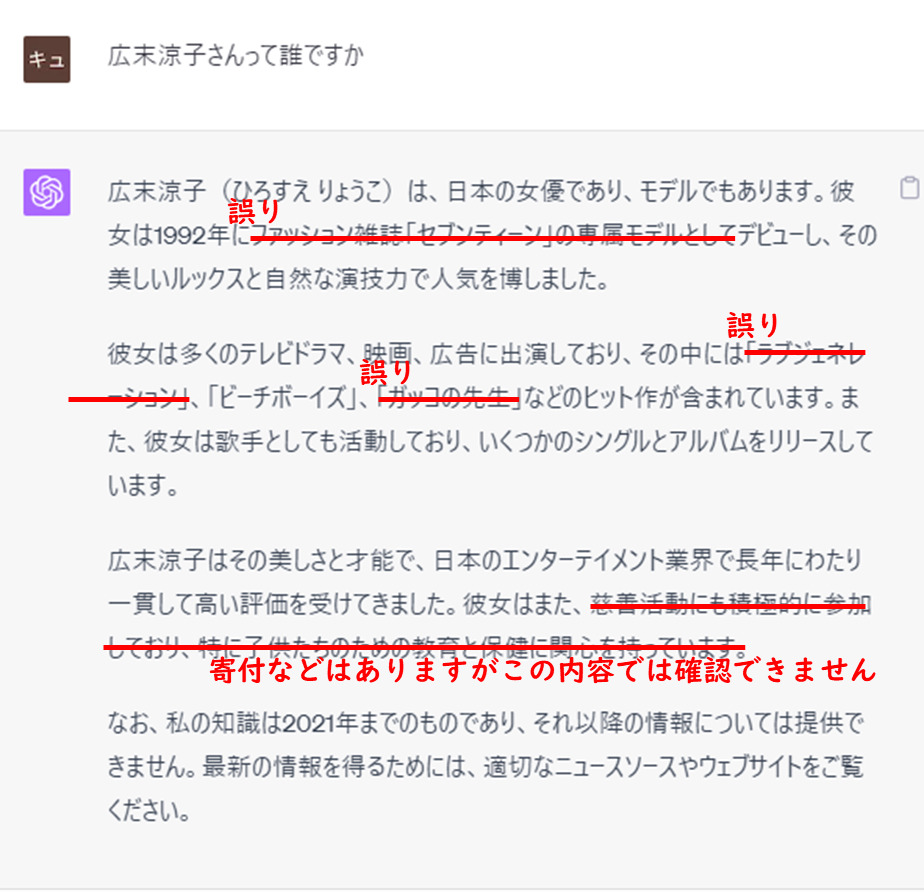
日本ではかなりの有名人ですが、学習データの上ではまだまだ具体的な学習が追い付いていないのかもしれません。
米国の著名人の来歴を、英語で質問しても、虚偽が混じるChatGPT
英語に強いと言われるChatGPTですが、GPT3.5ではそれでも誤りが混じります。
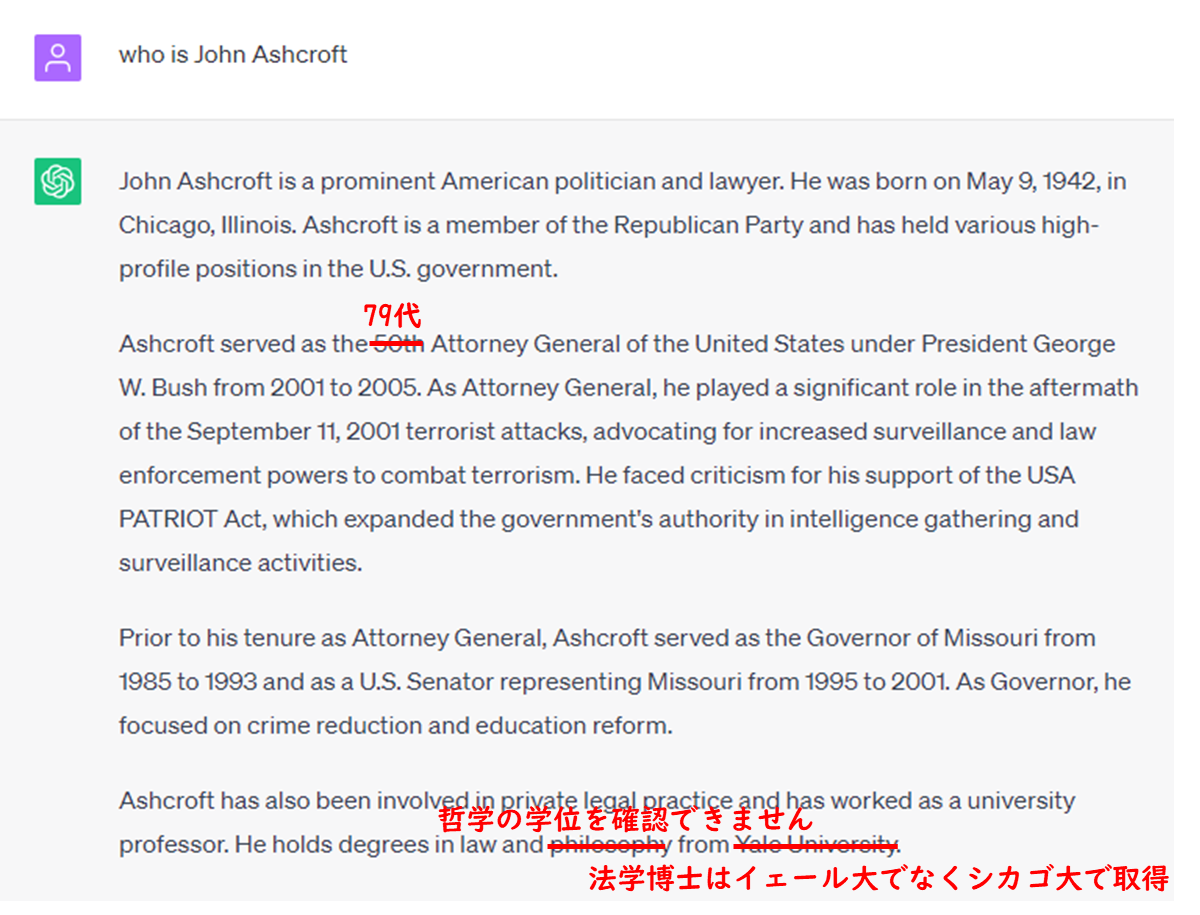
GPT-4は正しい回答
同じ質問に対し、GPT-4は、当方で確認できる限り正しい事実を回答しました。
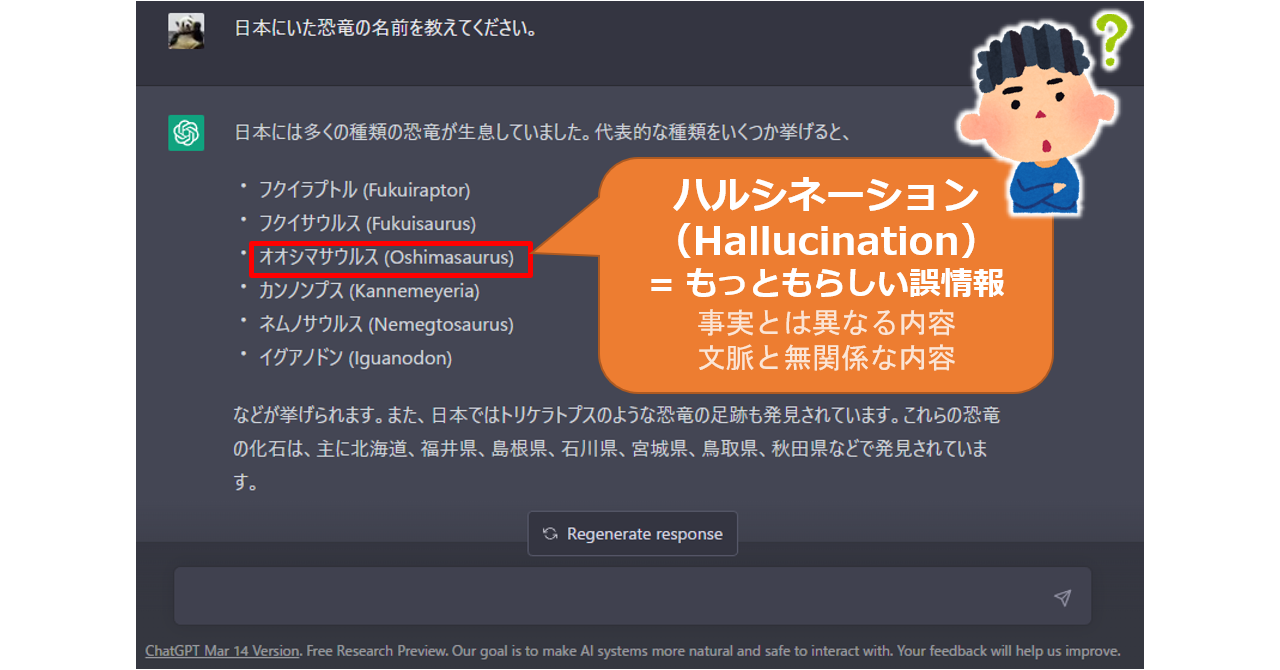
AIがもっともらしいウソをつく現象「ハルシネーション」
大規模言語モデルに基づく対話型AIが、「もっともらしいウソをつく」現象を「ハルシネーション」というんだそうです。
LLMの仕組みは残念ながら専門外ですが、その仕組みについては、おおむね次のような説明がされていると思います。
LLMは膨大なデータで訓練されている
ほとんどのLLMは、言語処理に適した工夫がされた「トランスフォーマー」と呼ばれるニューラルネットワークの構造を使用している。
…
トランスフォーマーは膨大な文章を読み取って単語や言い回しの関連性のパターンを見つけ出し、ある単語の次にどの単語が続くのかを予測する。
ChatGPTやBardの仕組みとは? 会話型AIを駆動する大規模言語モデルの裏側 WIRED
このような仕組みであるならば、もっともらしいウソ「ハルシネーション」が起きる根拠はある、と考えられます。
まず根本的にChatGPTやBardは、何が「正確」で何が「正確ではない」のかを理解しているわけではない。これらのシステムは訓練されたデータと一致する現実的で自然な回答を選んでいるだけなのだ。
例えば、ボットは次に続く最も可能性の高い単語を必ず選ぶわけではなく、2番目や3番目に可能性の高い単語を選ぶことがある。ただし、これが極端になると文章が意味をなさなくなるので、LLMは自己分析と自己修正を継続的に実施しているというわけだ。
ChatGPTやBardの仕組みとは? 会話型AIを駆動する大規模言語モデルの裏側 WIRED
感情がこもっているような回答であっても、そこにあるのは感情ではない。
事実を述べているようでも、そこにあるのは事実かどうかAIは認識していない。
すべては、「学習データに基づく確率」だというわけです。
「うそをつくAI」をどう有効に使えるか、使えないのか
「ハルシネーション」の問題は、早くから認識されており、これを抑制・軽減するための対策がいろいろと試みられています。
OpenAIは新たな研究論文に関する投稿記事の中で、AIモデルをより論理的に動作させてハルシネーションを回避する方法を発見したかもしれないと述べている。
同社は、複雑な数学の問題を解く能力を備えたモデルを「プロセス監視」で学習させた。プロセス監視とは、1つのステップごとにフィードバックを提供する手法だ。これに対し、「結果監視」は最終結果に基づいてフィードバックを提供する。
OpenAI、AIモデルの「幻覚」を軽減する手法を報告 ZDNet
ハルシネーションを「軽減」することに意味はあるのか?
しかしながら、ハルシネーションを「軽減」する、ということを目標とするならば、それは対話型AIの根本問題の解決にはならないだろう、というのが筆者の考えです。
嘘をつく回数が減っても、嘘は嘘
例えば、20%の頻度であった嘘を、10%の頻度に軽減したとします。
これではまだまだ足りないでしょう。
では、嘘の頻度を1%、いや、0.1%に軽減したらどうでしょうか?
99.9%は嘘がない回答が返ってくるならば、私たちはそのAIを「信用して大丈夫だろう」と考えるかもしれません。しかし、その結果は、0.1%の嘘を、無検証で信用してしまうリスクにつながらないでしょうか?
このようなわけで、ハルシネーションの「軽減」の努力は、実はほとんど報われないのではないか?と考えているのです。
まったくの役立たずだと悲観する必要もなさそう
それでは、原理的に嘘をつくことが避けられない対話型AIは、結局のところ役立たずなのでしょうか?
そんなことはないと考えています。
単純な条件分岐や抽出によらず、動的に回答を生成できる能力は、これまでのどんなクエリよりもすぐれています。
使い方によっては、ハルシネーションの影響を排除することも可能ではないかと思います。
すでに発表されているソリューションの中から、いくつか見てみたいと思います。
学習データを制限することで、限定的にハルシネーションを抑制
この問題の解決策として、限定されたデータを用いてGPT-4を利用できるようにしました。
また、プロンプトのトークン制限問題についても独自の手法で解決し、大規模データの登録も可能になりました。
このアプローチにより、GPT-4が生成する情報の正確性と信頼性が向上し、企業やユーザーにとってより安全で有益な人工知能となります。
限定されたデータを利用することで、AIは正確性や信頼性に優れた情報提供が期待でき、ハルシネーションのリスクを軽減するとともに、ユーザーのニーズに適した情報生成が可能となります。
GPT-4を自社専用化!信頼性ある情報提供を実現する 情報特化型自然会話AI作成サービス「Nolie」が誕生
このアプローチからは、次のような有効な対策が読み取れると思います。
- 学習データを目的に合わせて制限している
→「うそをつくための材料を与えない」ことを意味します。 - 利用範囲を限定している
→学習データと無関係なプロンプトが入力されることを防ぎ、また、仮にうそをついた場合でも、影響を小さくおさえることができる、と考えられます。
ふたつめの点は、記事本文にははっきり書かれていないんですけれども、
「ウソをつく」可能性をゼロにできないとすれば、仮に万一ウソをついても、致命的な影響が発生しない範囲に用途を限定することは、有効ではないかと思います。
「ハルシネーションが発生しない」とするサービスも
ハルシネーションを「軽減」ではなく「発生しない」とするソリューションも見られます。
弊社の独自アルゴリズム「意図予測検索」は、FAQに入力された言葉から検索者が何を知りたいかの「意図」を予測し、その意図に合致する質問をすばやく検索するシステムです。
…
HelpfeelがAIのハルシネーションを回避しながら検索精度を30%向上させる「Contact Sense AI」を公開。問い合わせの自己解決を促進
本アルゴリズムはAIが回答を逐次生成するのではなく、あらかじめ用意された展開済みの質問文を検索するため、ハルシネーションを回避し正確性を担保しています。このアルゴリズムの提供によってユーザー企業のさらなる問い合わせの削減と業務負担の軽減を支援してまいります。
このアプローチでは、
- 回答文はあらかじめ用意され、人間がうそでないことを確認している
→この方法であれば、ズレることはあっても、うそをつく可能性はゼロにできると考えられます。 - ユーザーの意図をくみとるためにAIを使用している
→AIの直接の出力を受け取るのは、検索システムであって、ユーザーではないとみられます。どの回答文を選択するべきか、という目的に合わせたプロンプトを投げているのでしょう。
自分の文章の書き直しは、ほぼ問題なし
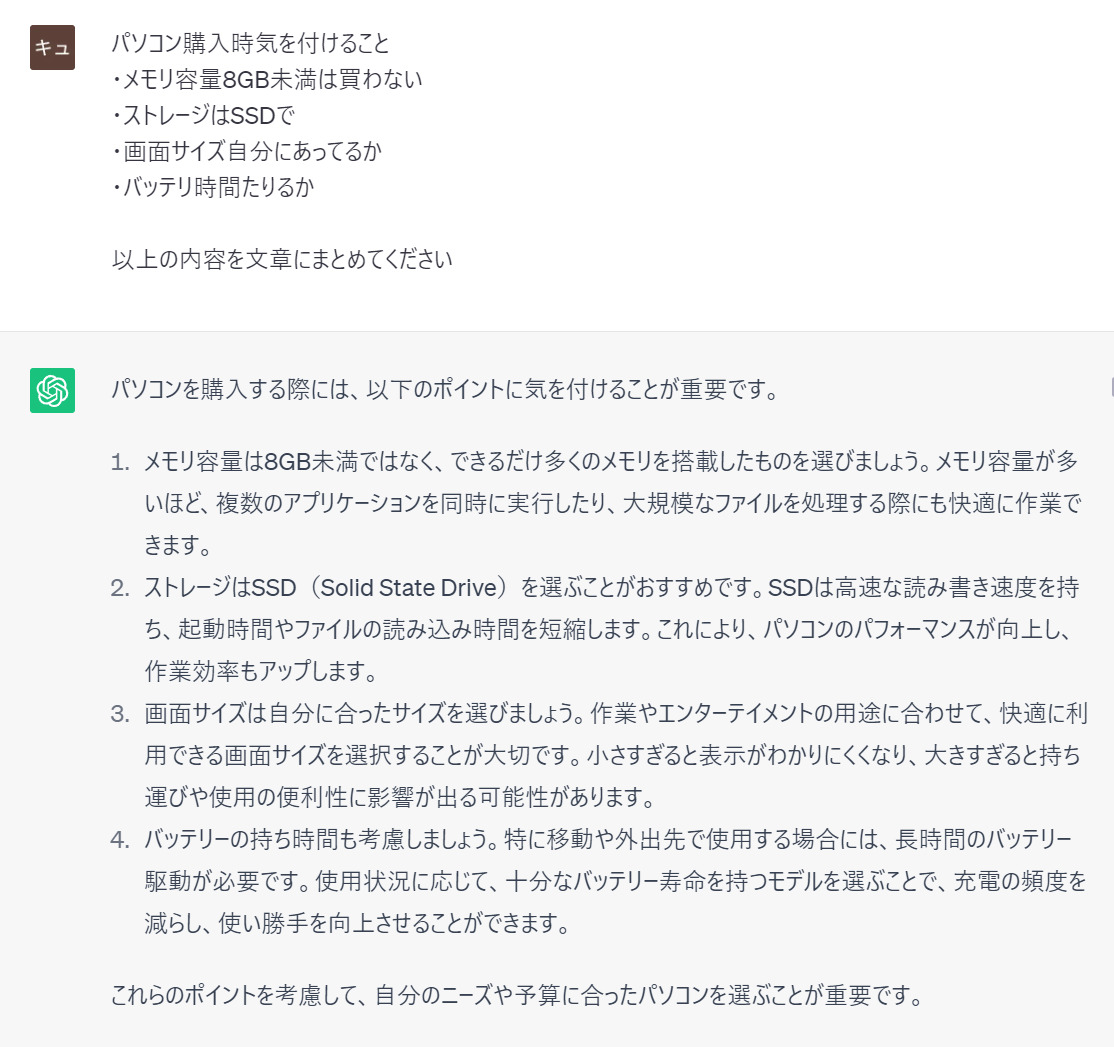
箇条書きで急いで書いた要点を、文章に書き直す、といった用途では、ほぼ問題なく使用できます。作業時間と労力を大幅に軽減できます。
上の例では、「メモリ容量が多いほどよい」の部分は少々書きすぎですが、他の部分はだいたい意図したとおりの文章を組み立ててくれています。
ただし、自分で書いていない事柄の説明を書き加えられている場合は、その部分の事実の検証は必要だろうと思われます。
新しい課題に対して、アイデアを出してもらうのも便利
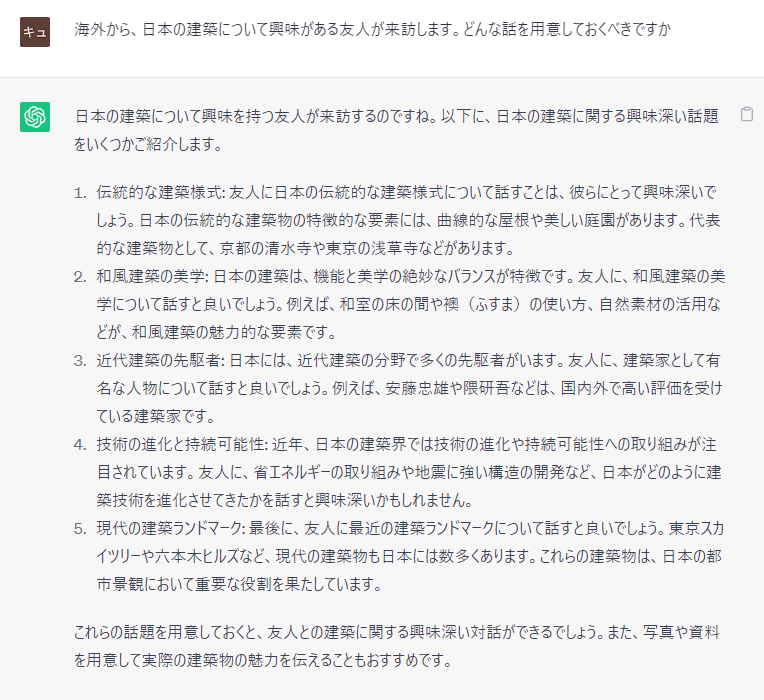
※スマホでは、二本指でのばすと拡大して見られます。
どこから考えたらよいか分からない。何から検索してよいかも分からない。そんなときに、アイデアを求める相手としては十分に使えると考えています。
アイデアの一部が間違っていることもある
出てきた回答の中には、ウソが含まれる可能性があります。
例えばこの例です。「エクセルの練習問題を作る」プロンプトに対する、GPT-4の出力です。

例えば「1.データの作成」のセクション、この通りにワークシートを作成すると、次のようになります。
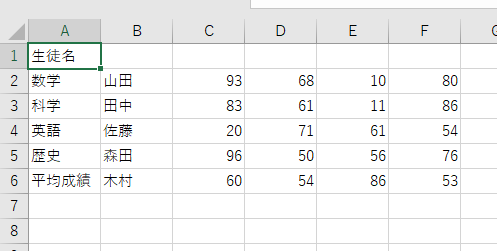
これでは、生徒の成績表になっていませんね。例えば、次のように修正して使用するべきです。
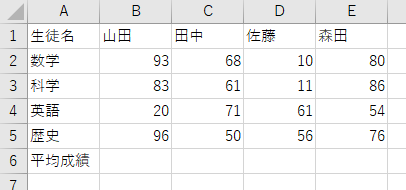
このように、GPT-4ですら、「よく読むとウソ」な回答が出てきます。
しかし、これはあくまでアイデアです。受け取った人間が、実際に試して確認することで、アイデアそのものは生かすことができます。
プログラミングは、理解して使えば十分に利用できる
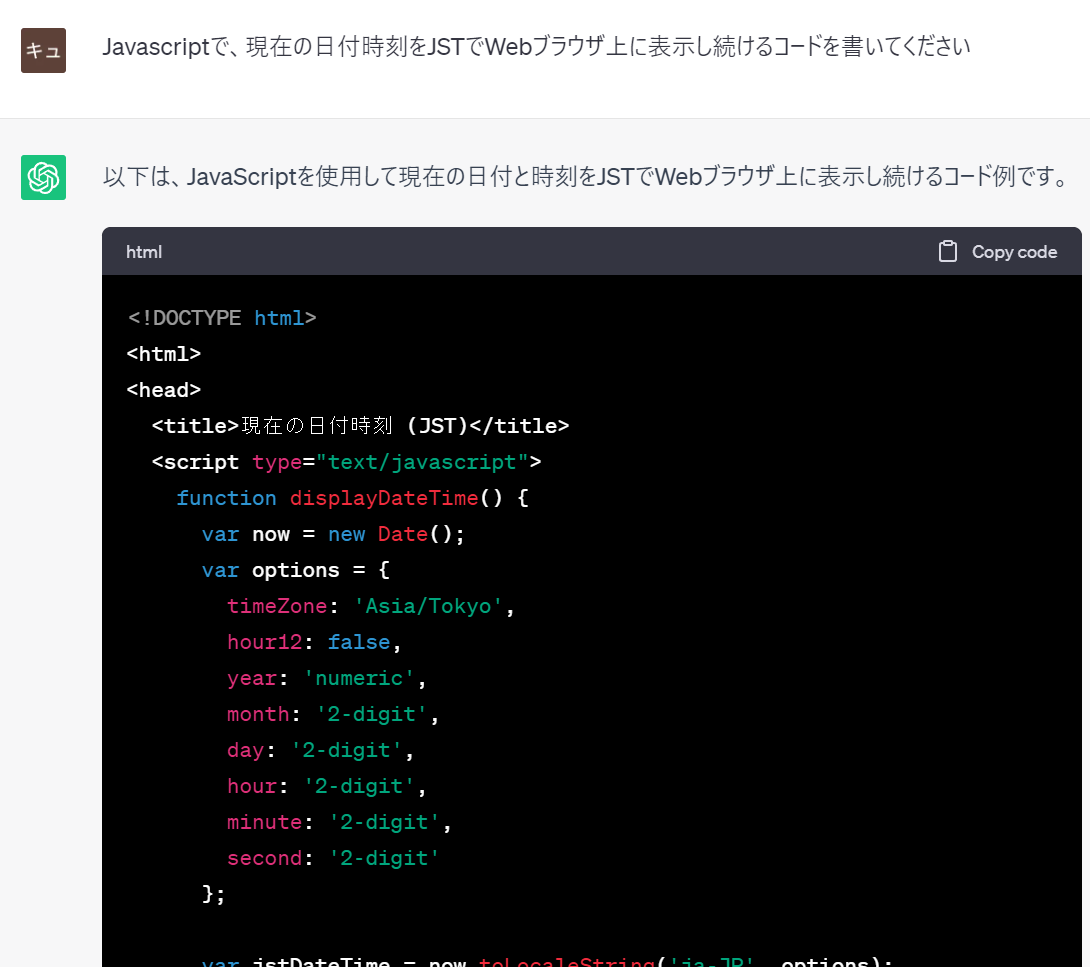
自然言語のプロンプトを使って、実際にコードが得られるのは、ChatGPTの素晴らしい特性です。
実際に、日々使用するツールのコーディングに使っています。
たまにハルシネーションは起きてます。しかし、
- 自分の理解できる言語に限定し、理解できる範囲で確認しながら使う
- 他に影響がない環境で、テストして確認してから使う
というような点に気をつければ、大変有用なツールです。
すでに、多くのエンジニアの方が、このAIをエディタに組み込めるサービスを使用して、生産性の大幅な向上を体験しておられると思います。

ただし、ここではむしろ、機密コードが無意識のうちに送信され、漏洩するリスクが強く意識されているようです。

検索エンジン × 対話型AI の、可能性と限界
対話型AIが、ウソをついたり、最新の情報に対応できない、といった理由で、対話型AIと検索エンジンを組み合わせた試みが始まっています。

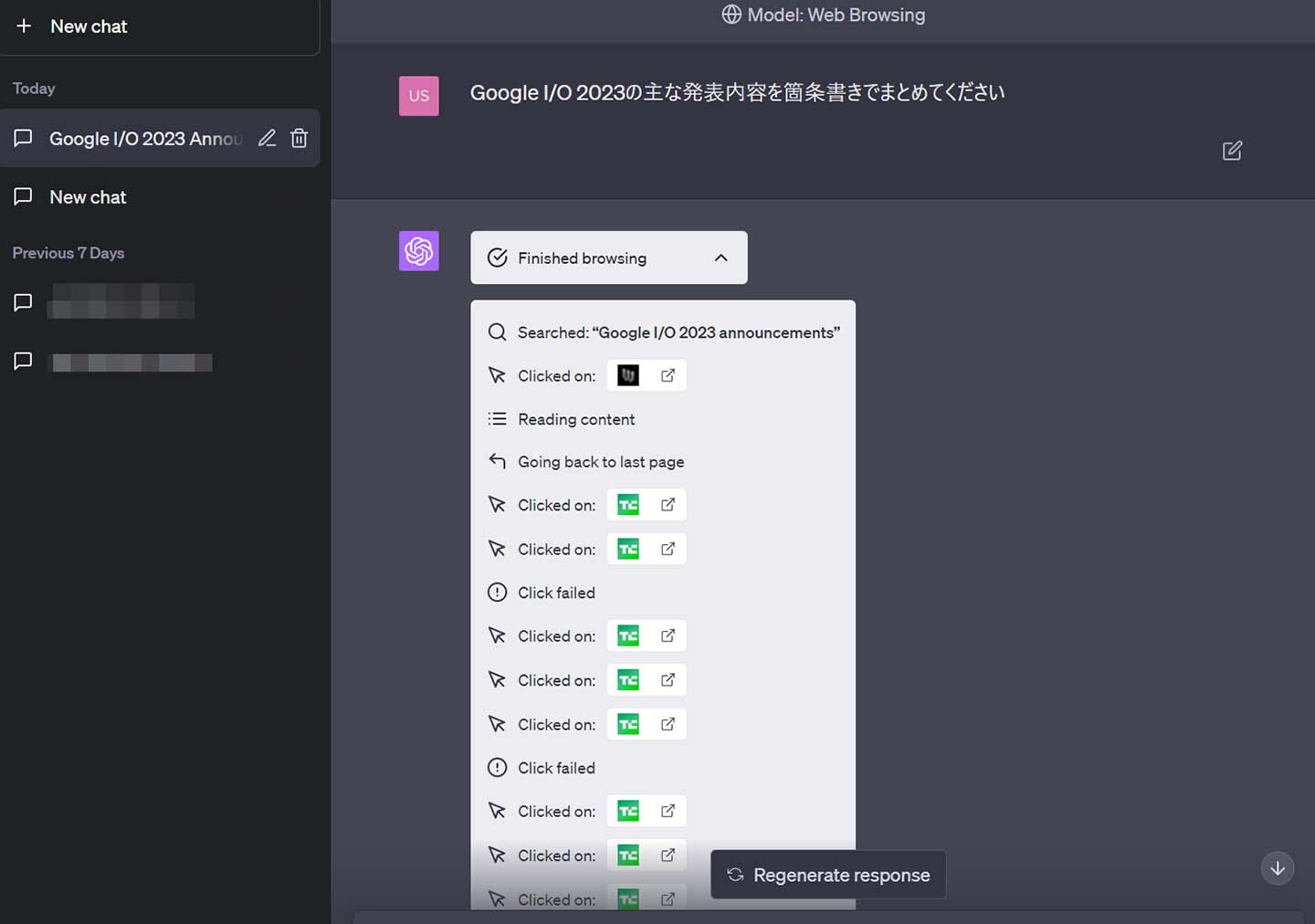
この方法は、ある程度、対話型AIの「うそをつく」限界をカバーしているように見えます。
確かにうそは少ないと思います。しかし、質問に対する回答として適切か、という部分には、疑問符が付きます。結局は人力でネット検索をするはめになる場合も、多く出るのではないでしょうか。
検索エンジンは、ただ最新の情報を取得できるだけでなく、人間が作成した真実のソースを検索してくる力を持っています。確かにフェイク情報も混ざりますが、それは検索した側で取捨選択できます。
これに対して、対話型AIに質問して得られた回答は、それを吟味し取捨選択する余地がありません。
冒頭で紹介した米国裁判所での事例のように、「それは事実であるか」とAIにたずねることの意味はなく、結局は、人間自身の知識や、検索エンジンに頼って、真実を見極めるしかありません。
「検索エンジンにAIがとってかわる」ことは、ないのではないか。
このように考えていくと、ChatGPT登場のときに言われたような「検索エンジンにAIがとってかわる」というようなことは、どうも起きないのではないか、と思えてきます。
実例で見てみます。
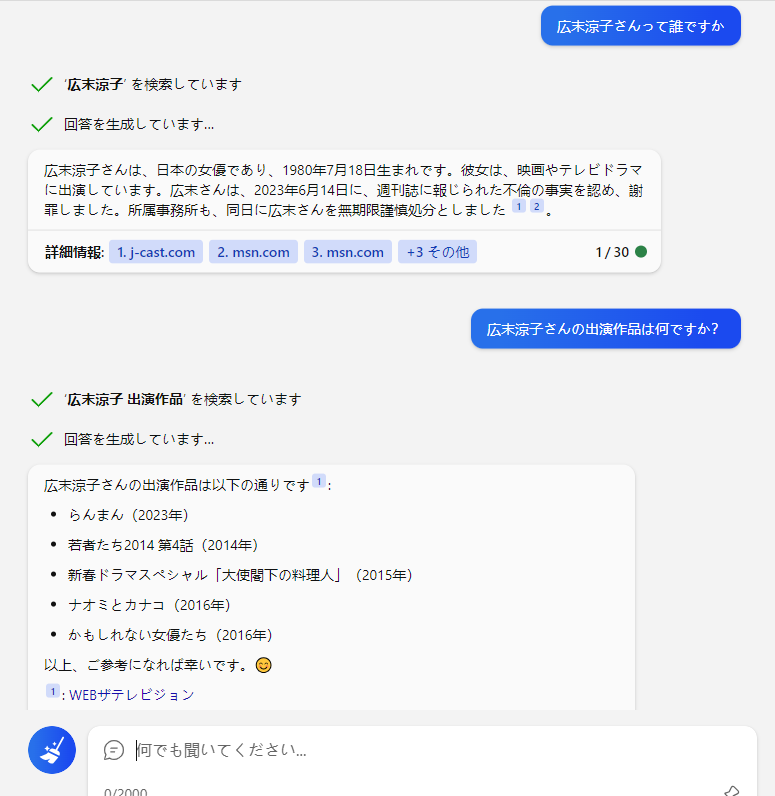
うそではないかもしれませんが、回答内容は不十分で、質問した人物についての全体像を明らかにするものとは言えません。
もっともこれは、使っている検索エンジンがBingだからかもしれません。たとえGPT-4と協働したとしても、Bingの検索はGoogle検索の足元にも及ばないクオリティです。
さらに、ネット検索を併用しても、ハルシネーションは起こっています。
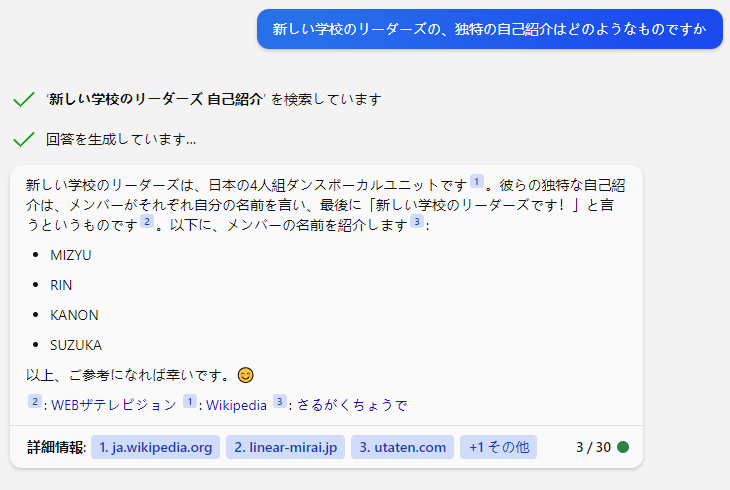
まったく同じ質問文を、Google検索に入れてみた結果は次の通りです。
Bingの回答「メンバーがそれぞれの名前を言い…」の部分は、ハルシネーションを起こしています。
明らかに、「さいしょからGoogleで検索すれば良かった」と思える事例です。
このようなことが積み重なれば、当初言われたほどの「検索エンジン離れ」は起きないかもしれない、と思わされます。
結論: 回答そのままでは使い物にならないが、まったく新しい可能性をきりひらくもの
結論として「対話型AIとどう付き合うか?」と問われれば、
このようにお答えせざるを得ません。
対話型AIの回答は、そのままでは全く使い物にならない
たとえ数%でも虚偽の事実が混じっている可能性がある回答を、そのまま使うことなど、まったく想定できないと思います。
ただし、対話型AIは、書く労力の削減や、アイデアが必要な時の「きっかけ」を与えてくれるものであることは間違いありません。
また、用途に応じてカスタマイズを行うことで、限定的に、「対話の自動化」に使うことができる場合もあります。
人間が読み切れる量を、はるかに超えるドキュメントを取り込み、それをもとに回答を生成する。このような特性をもった対話型AIが世に出た以上は、これを前提にしか次の時代は想定しえないだろうと考えています。
ですから、同時に、次のように結論できると思います。
対話型AIがある世界と、無い世界は、人間社会の発展可能性において天と地の差がある
この先、生成AIはどこへ行くのか
ChatGPT、GPT-4の登場で、一躍脚光を浴びた対話型AIですが、OpenAIのサム・アルトマン氏は、この延長で新しい進歩はもはやない、と考えているようです。

画像生成AIも、さまざまな用途に活用されていますが、一方で問題点が指摘されることも多くなってきました。

「AI成果物をAIが学習することでモデルが崩壊する」との指摘
もともと、LLMやその他のトレーニングに用いられるデータは、書籍やインターネットの記事、写真やイラストなど人間が過去に人工知能の助けを借りずに作成していたものです。しかし、ジェネレーティブAIの発展に伴い、AIでコンテンツを作成してインターネット上に公開する人が増えた影響で、学習の元となるトレーニングデータに影響が出ていると懸念されています。イギリスとカナダの研究者グループは2023年5月末、「再帰の呪い」と題した論文をオープンアクセスジャーナルのarXivに発表しました。論文では、「ジェネレーティブAI技術の将来にとって、憂慮すべき事実が明らかになっています」と述べられています。
AI成果物が急増したことで「AI生成コンテンツをAIが学習するループ」が発生し「モデルの崩壊」が起きつつあると研究者が警告 Gigazine
生成AIの急速な発展が、その限界をも急速にあぶり出しつつあるか
ここ一年、いや、ほんの半年ほどの間に、私たちの周りには生成AIが驚くほど急速に浸透し、その出力を見ない日はないほどになりました。
生成AIの発展は、ある特異点を突破し、爆発的な発展の段階に至ったものでしょう。
2023年は確かに、「新たな産業革命」とも言える、人類史の画期点になったと言えるでしょう。
そのことが、同時に、「人間の成果物を多量に学習して回答を生成する」、という現在の生成AIの限界点を、きわめて急速にあぶりだしているのではないか、と考えています。
新しいブレイクスルーは、おそらくそれほど遠くないでしょう。たんなる学習の量的拡大や、学習物の異なる処理方法に頼らない、新たなアーキテクチャが、水面下で準備されつつあるのではないか、と見ています。
コメント