テーブル形式のデータの読み込みには、めっぽう強いPower Queryですが、
「このページのここんとこの文字だけ読み込みたい」
というのは、なかなか苦手です。
そのやり方のメモです。
Webページをソースとしてデータを読み込む
まずは「データの取得と変換」→「Web」から
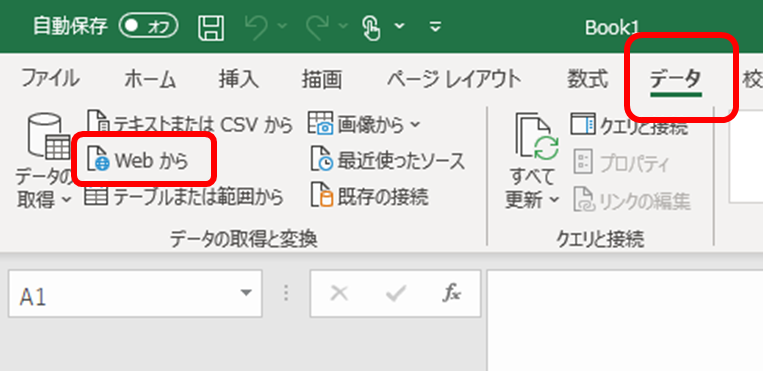
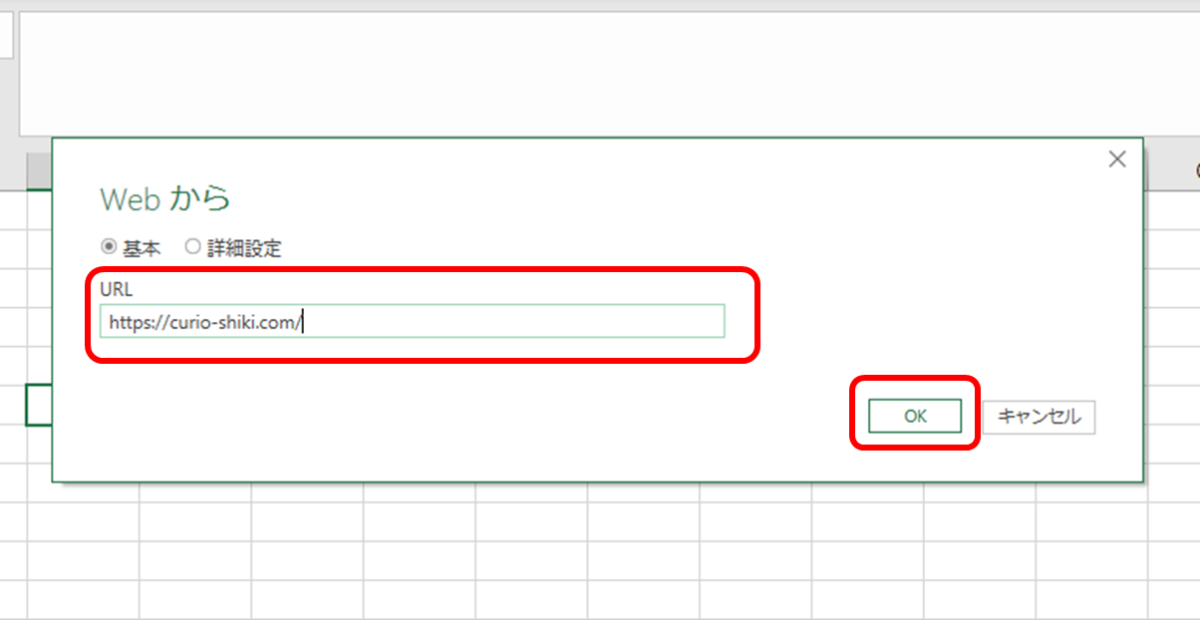
この次の画面では、いったんWebページをテーブルとして解析したツリーが示されますが、ツリー最上層のところで右クリック→「データの変換」
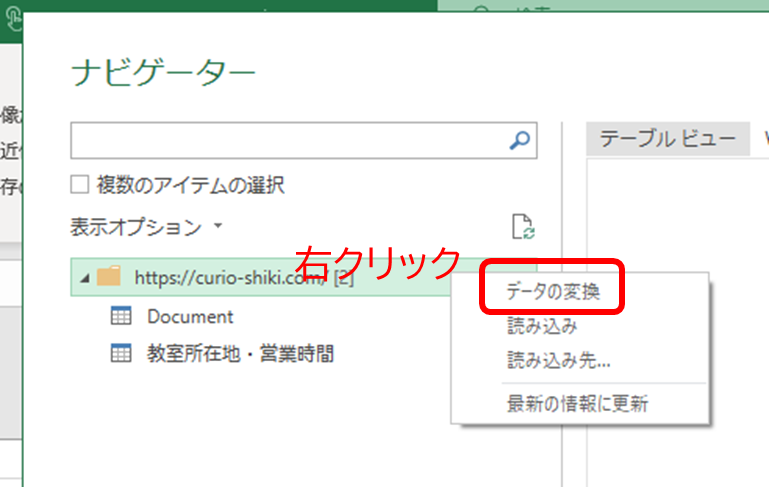
これで一旦、Webページ全体がソースとして読み込まれます。
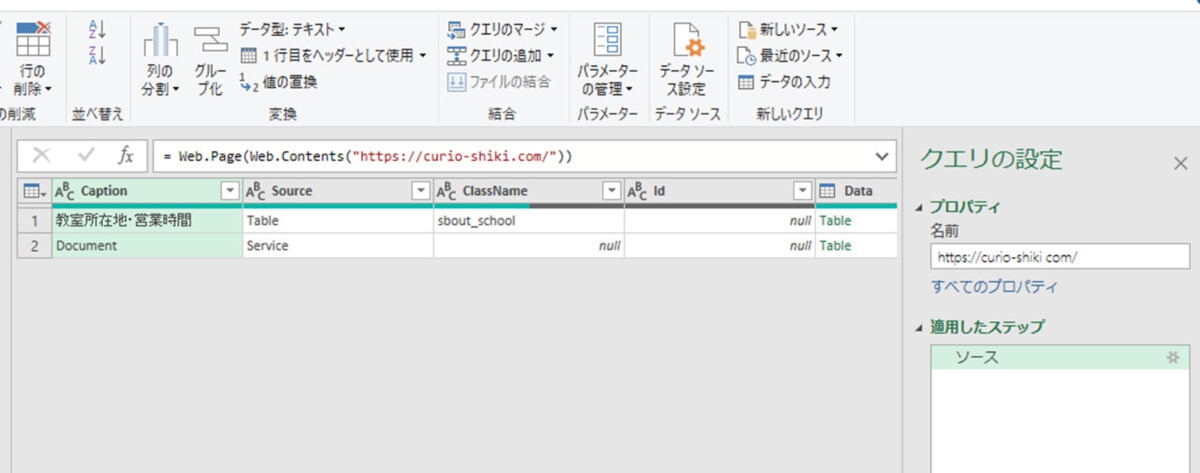
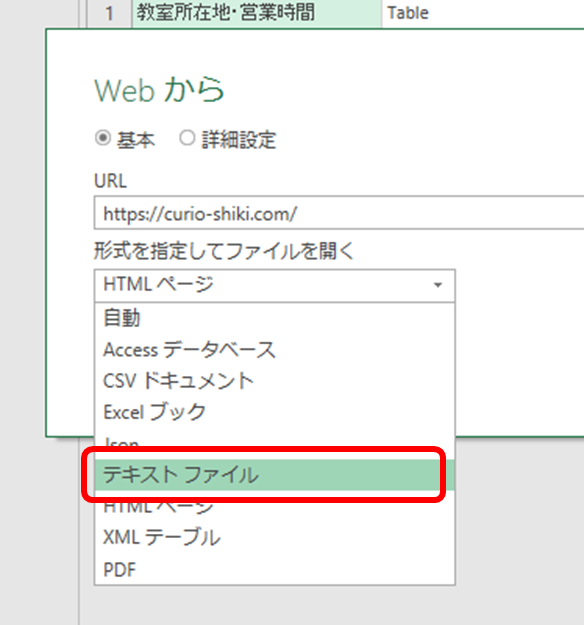
データ形式をHTMLからテキストに変更
いまの画面の右端、「適用したステップ」のところから、「ソース」のステップの設定変更をします。
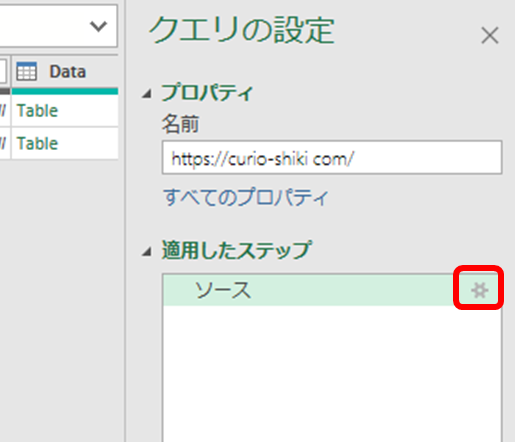
データ形式を「テキストファイル」に変換
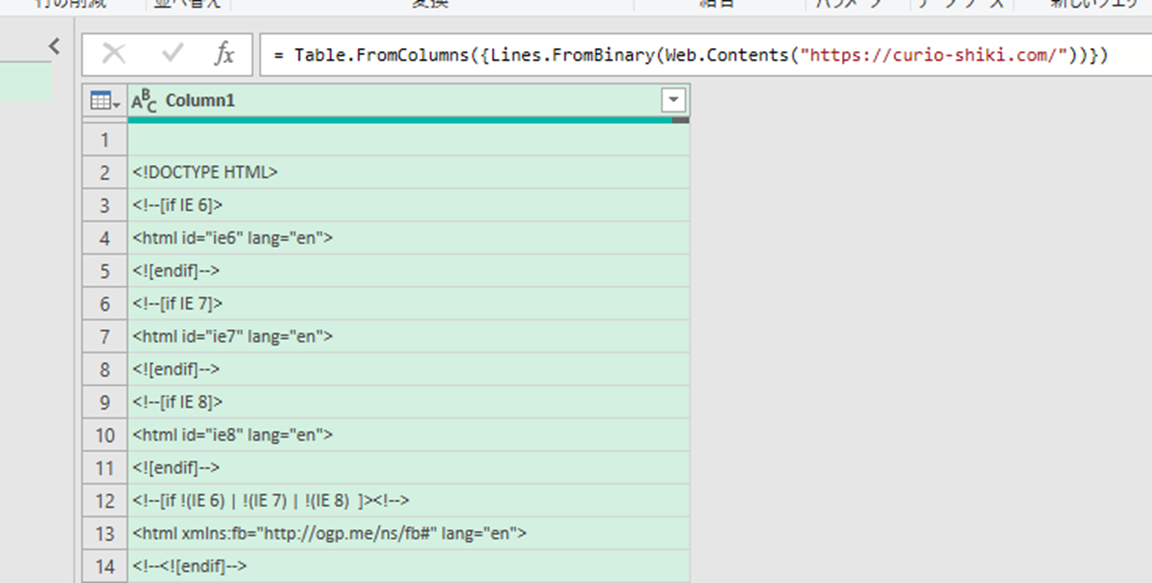
これで、ソースをそのままエディタで開いた感じの読み込み方式に変更されました。
読み込みたいテキストだけが残るように絞り込み
あとは、実際に読み込まれたデータを見ながら、欲しいものだけが残るように絞り込みをします。
フィルタによる絞り込み
例えば、リンク先をすべて抽出するのであれば
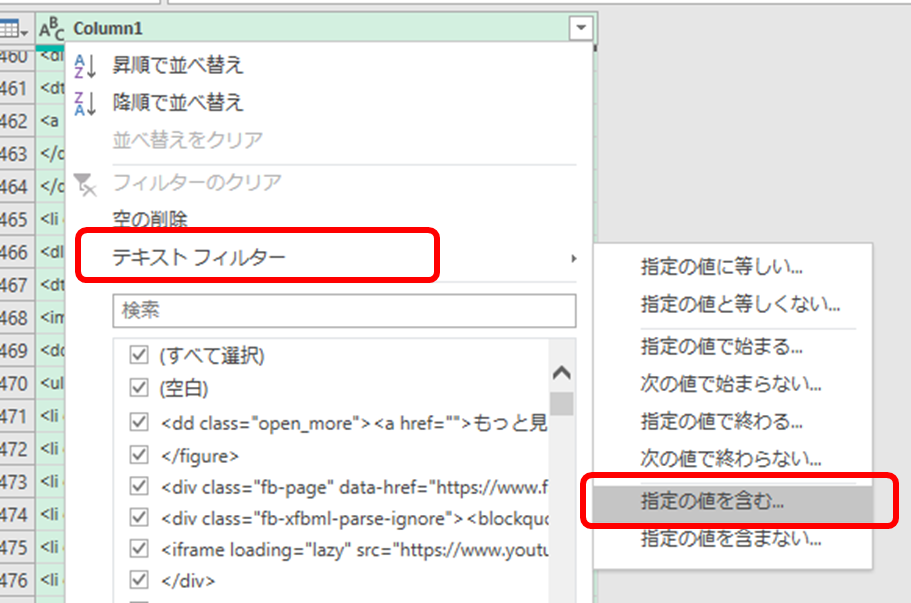
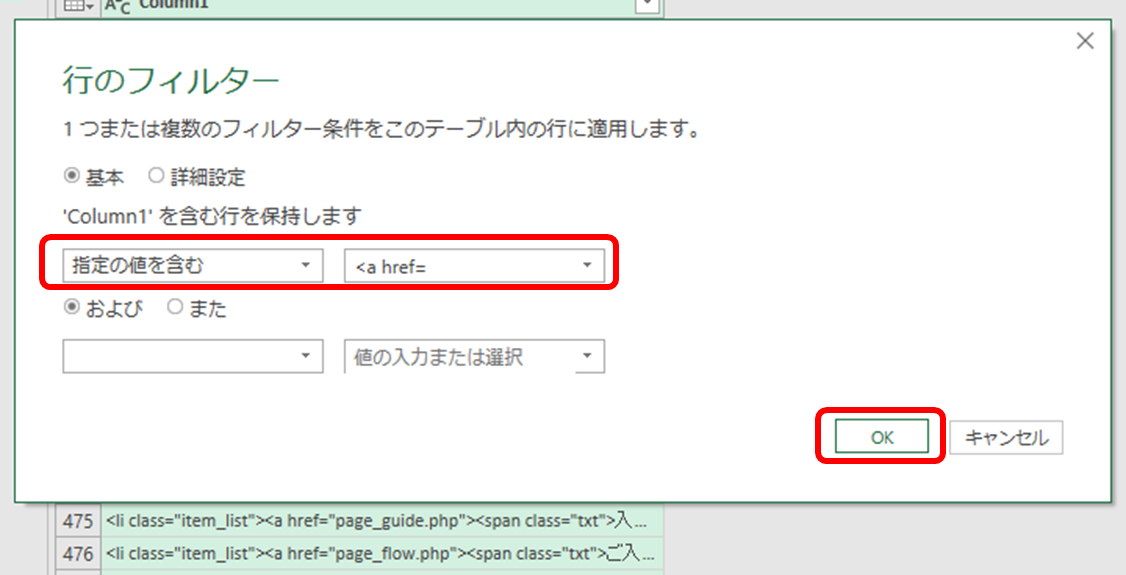
こんなふうに、特徴的な文字列を使ってフィルターすれば
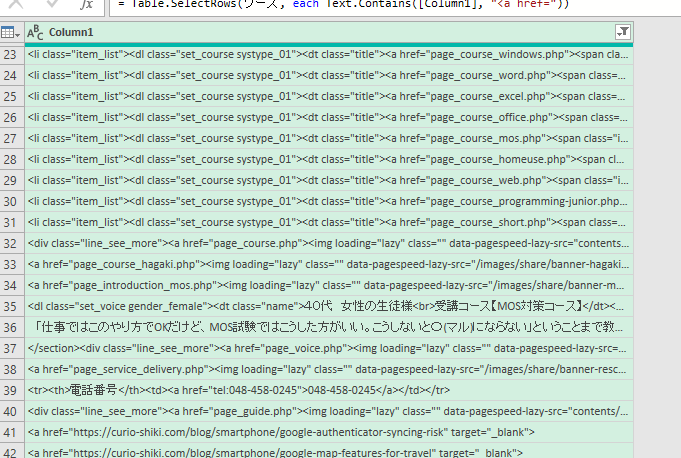
こんな感じで出てきます。
「列の分割」を使ったクレンジング
これではまだ汚いので、
一例ですが、例えばこういうことをやると
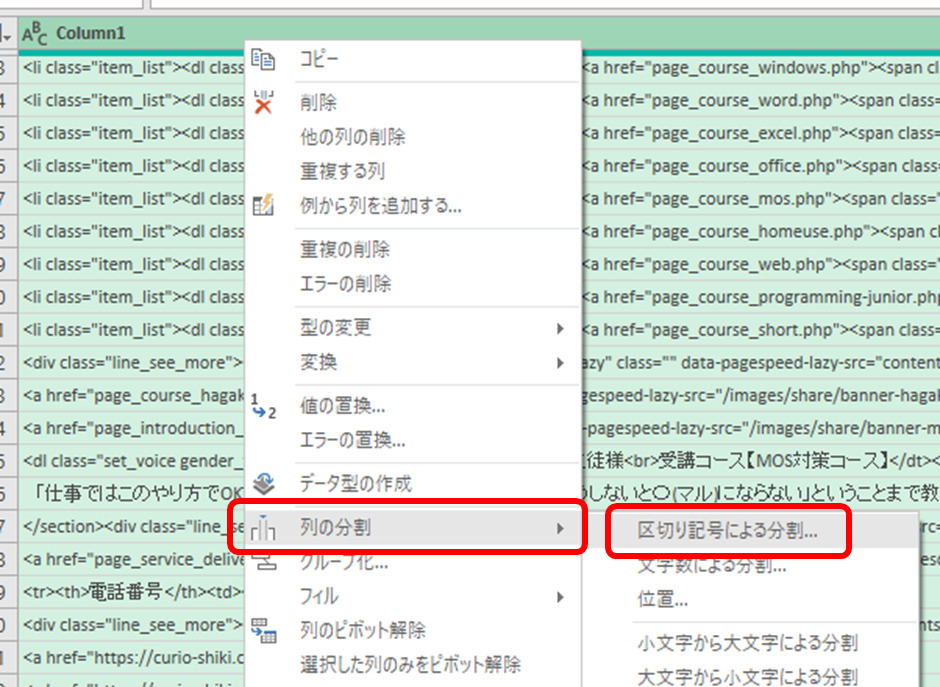
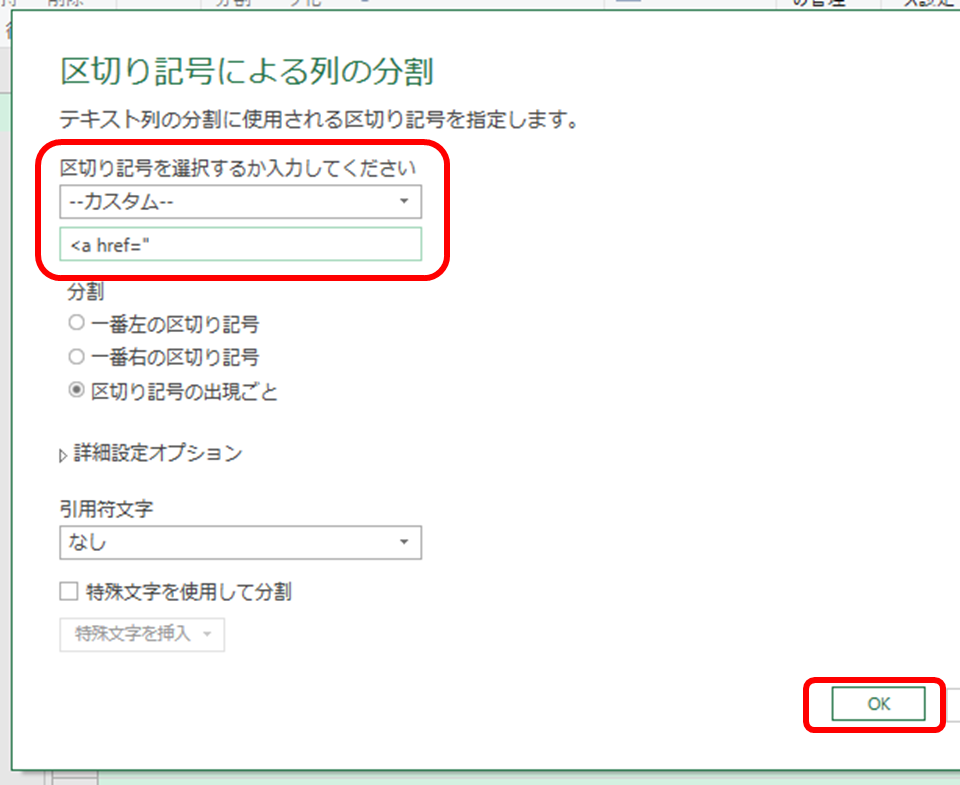
この操作で、<a href=” のところで分割され、かつ、<a href=” そのものは消えた状態になります。

「区切り記号の出現ごと」をチェックしたので、一行に複数のaタグがあれば、列がたくさんできるはずですが、1列しか増えなかったので、一行に複数のaタグが存在する事例はなかったようです。
もし複数の列がどどっと増えるようであれば「その他の列のピボット解除」を使ってたて並びに変換して次のステップに進みます。
ここでもう一度、a タグの終わるところの「”>」に着目して列を分割します。
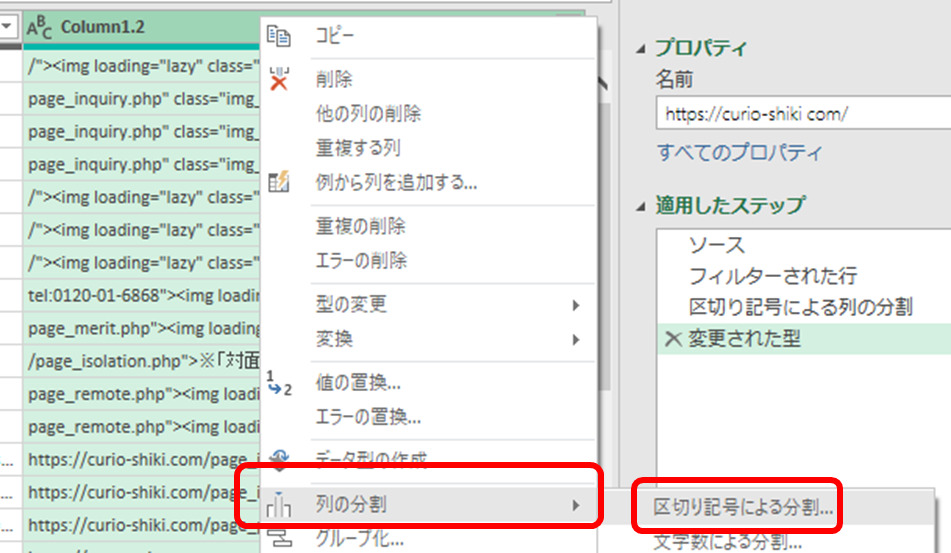
今回は、ターゲットにした aタグの閉じカッコだけで分割したいので「一番左の区切り記号」をチェック
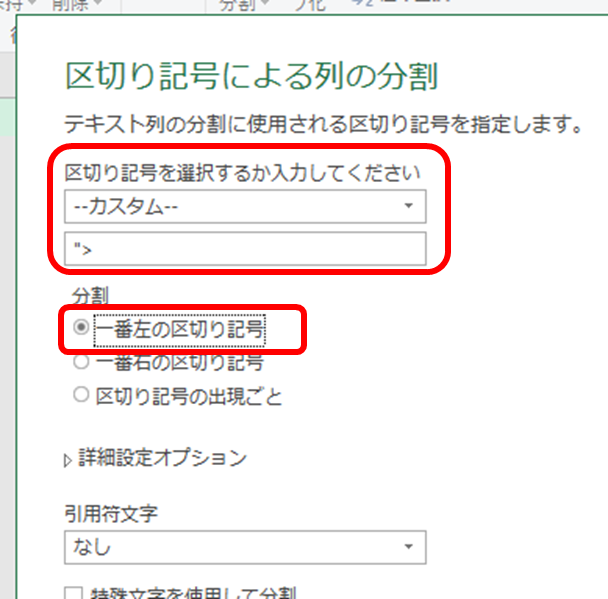
まだ少し余計なものがくっついていますが、aタグの中身だけを取り出すことができました。
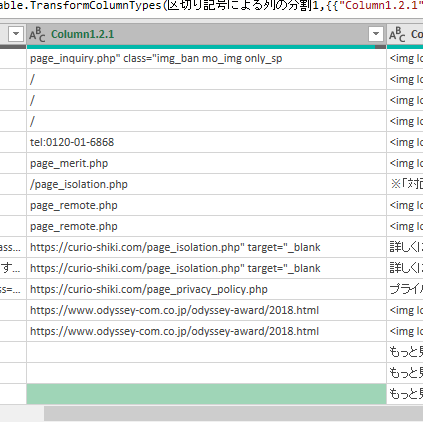
同様にして、 class や targetを分割によって取り除いていくと、リンク先URLだけのデータを作ることができます。
インデックス列を使った絞り込み
以上とは別に、「ここからここまでの行が欲しい」とはっきりしている場合には、インデックス列を使うといいかなと思います。
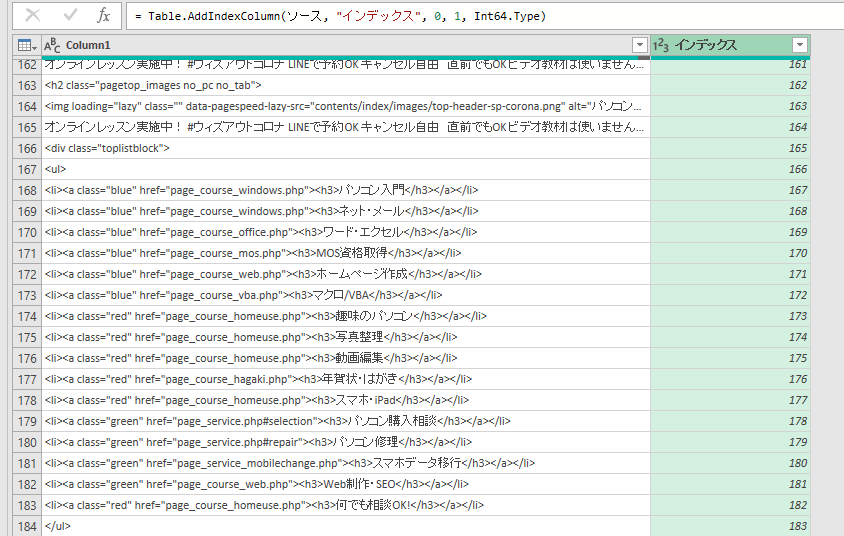
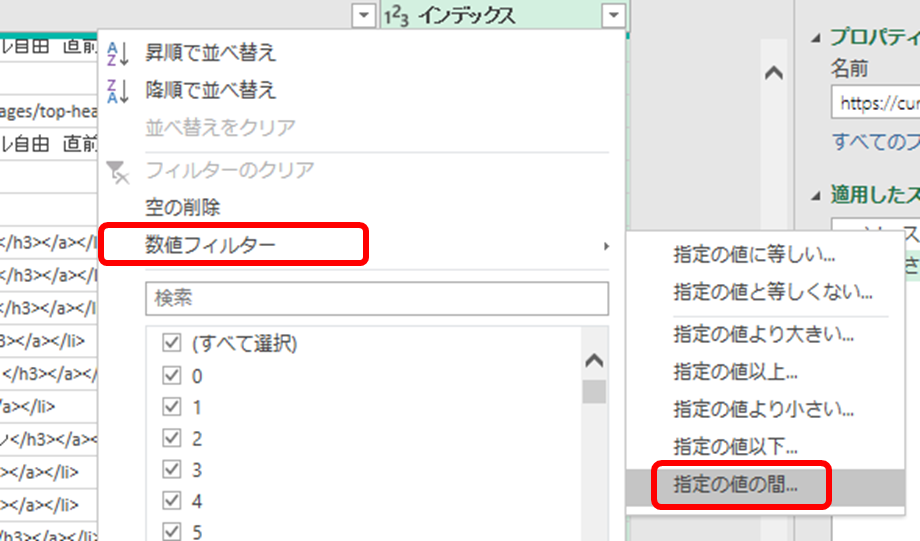
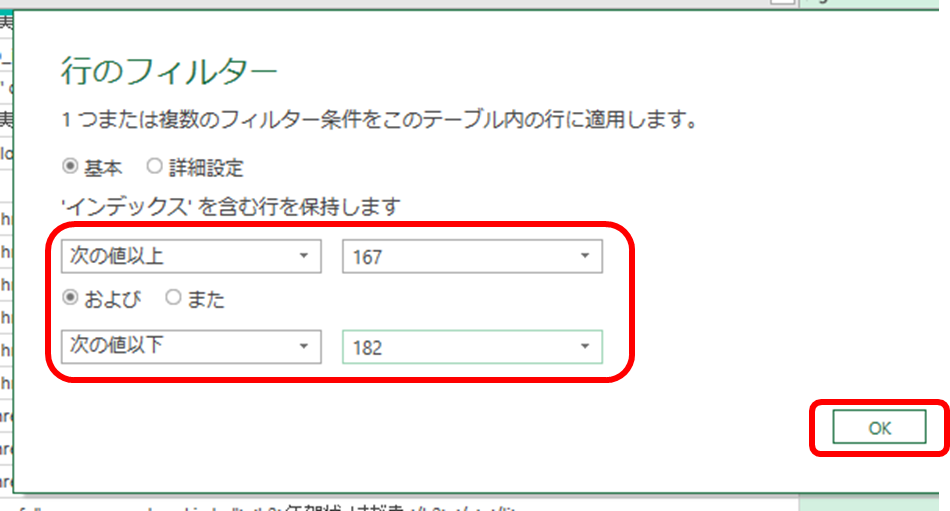
例えばインデックス167から182までの行を取り出すのであれば
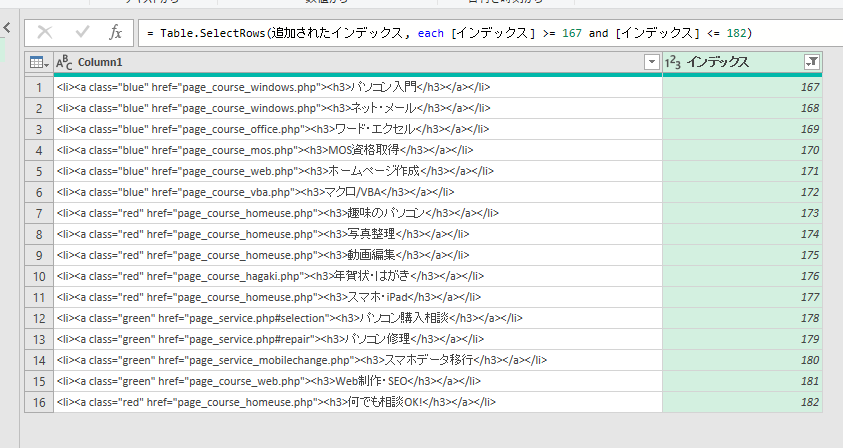
目的の範囲だけが取り出されました。
コメント